推理端点(专用)文档
快速入门
并获得增强的文档体验
开始使用
快速开始
在本指南中,您将仅需几分钟即可使用推理端点部署生产就绪型 AI 模型。请确保您已使用 Hugging Face 帐户登录 推理端点 UI,并且已设置付款方式。如果尚未设置,请在您的账单设置中快速添加有效的付款方式。
创建您的端点
首先导航到推理端点 UI,登录后,您应该会看到一个用于创建新推理端点的按钮。单击“新建”按钮。
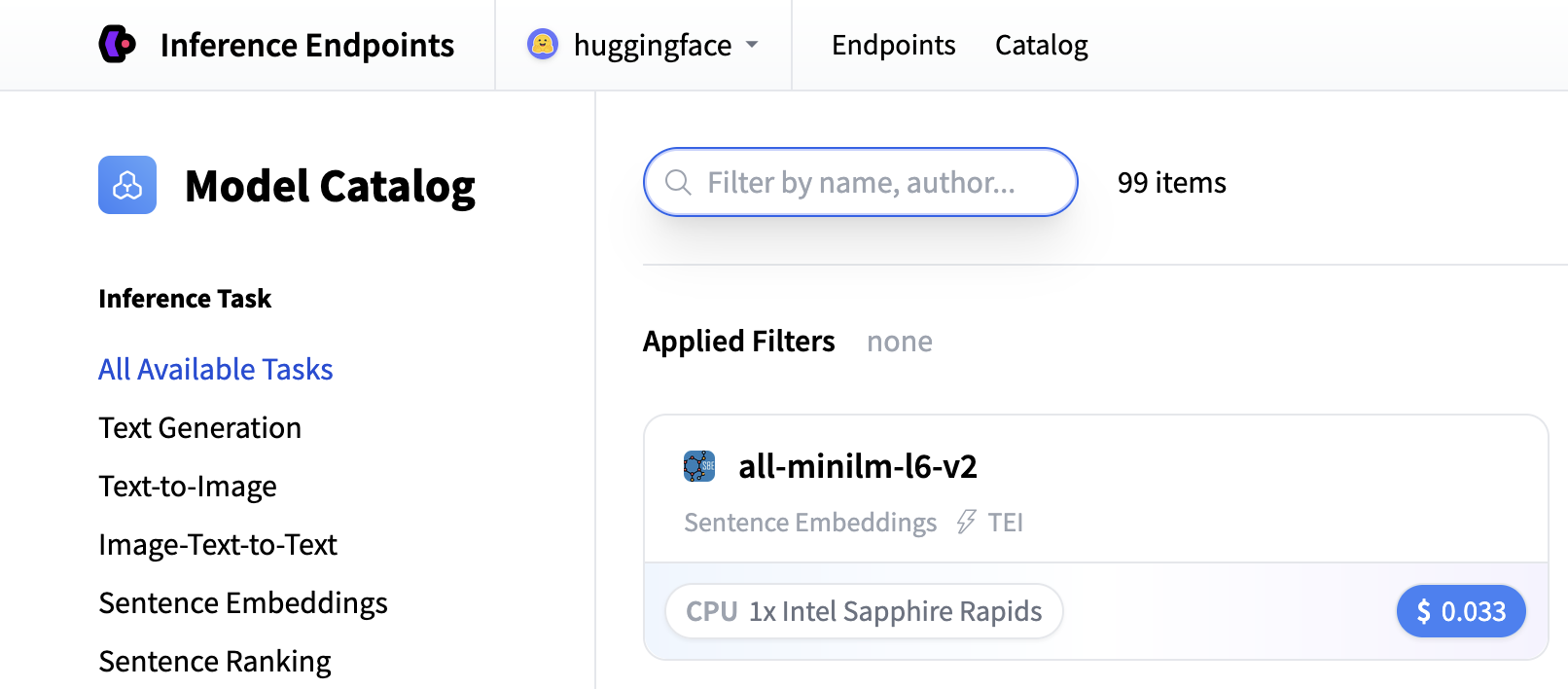
从那里您将被引导到目录。模型目录包含流行的模型,这些模型已调整配置以实现一键部署。您可以按名称、任务、硬件价格等进行筛选。
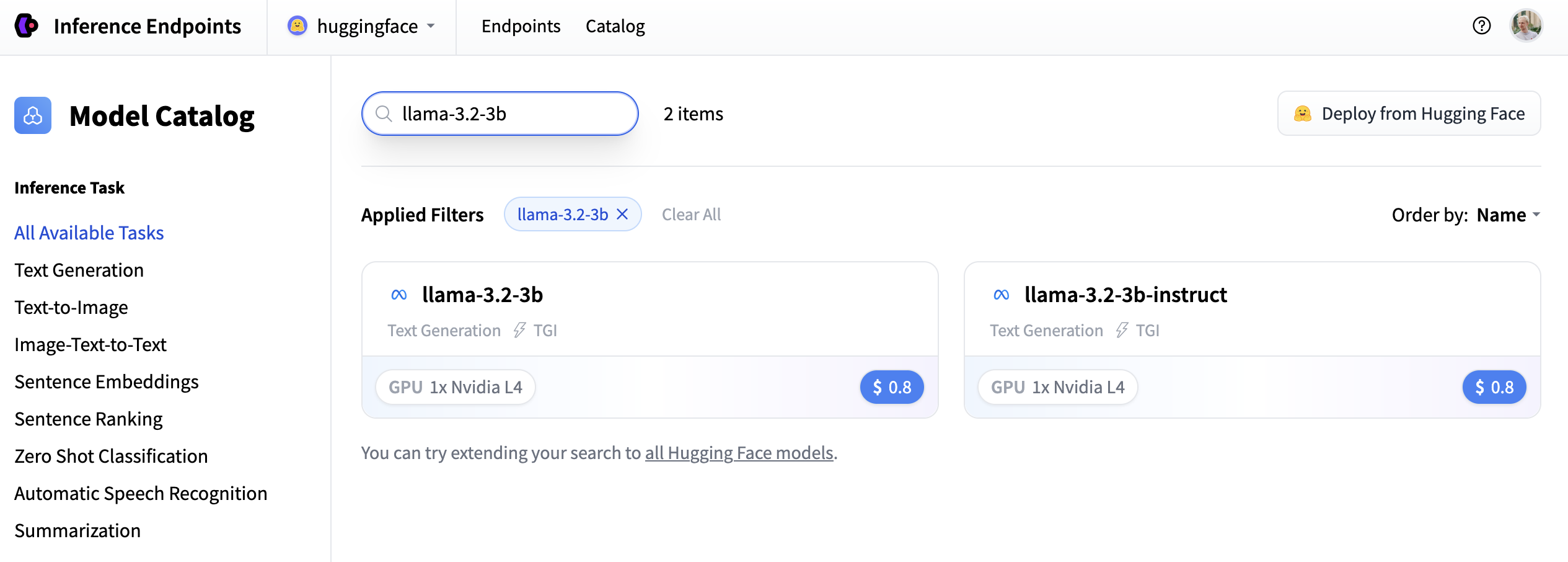
在此示例中,我们部署 meta-llama/Llama-3.2-3B-Instruct 模型。您可以通过在搜索字段中搜索 llama-3.2-3b 来找到它,然后单击卡片进行部署。
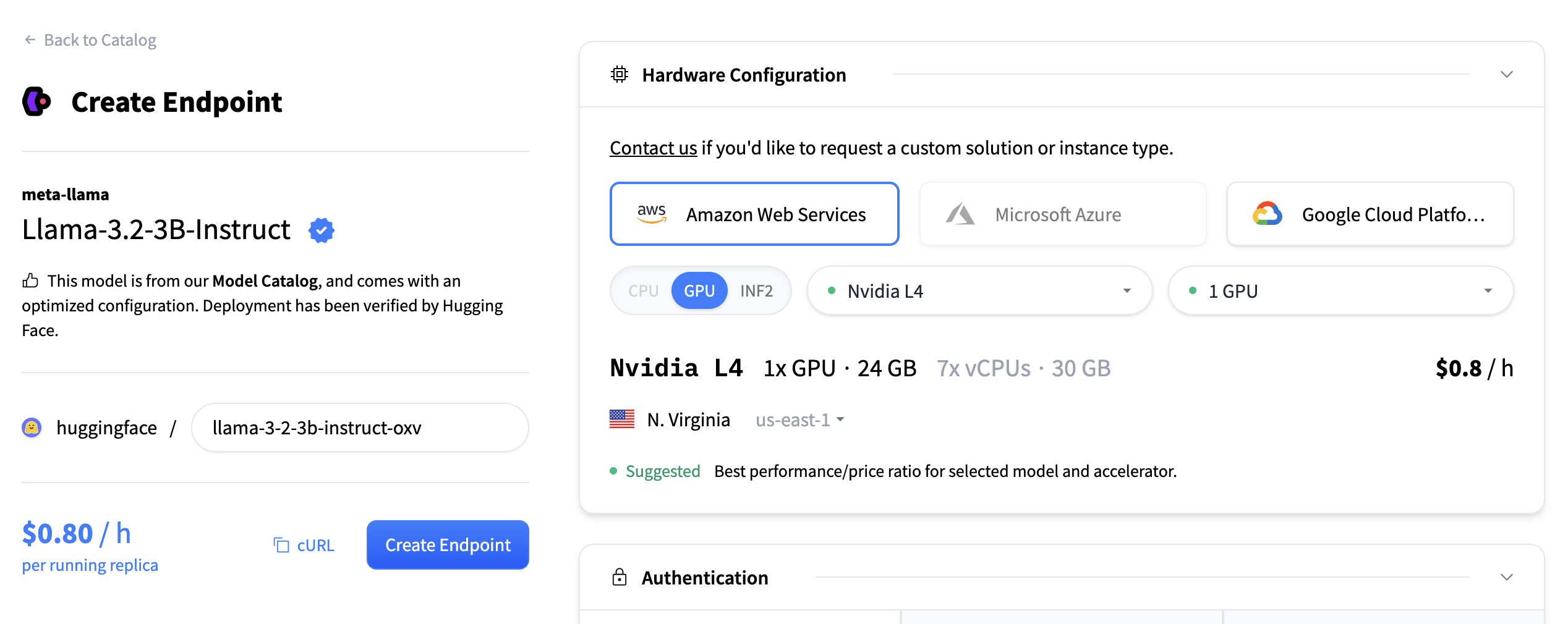
接下来,我们将选择硬件和部署设置。由于这是一个目录模型,所有预选选项都是非常好的默认值。因此在这种情况下,我们无需更改任何内容。如果您想深入了解不同设置的含义,可以查看配置指南。
对于此模型,建议选择 Nvidia L4。它非常适合我们的测试。性能良好且价格合理。另请注意,默认情况下,端点将缩减到零,这意味着它将在不活动 1 小时后变为闲置状态。
现在您所需要做的就是点击“创建端点”🚀
现在我们的推理端点正在初始化,这通常需要大约 3-5 分钟。如果您愿意,可以允许浏览器通知,当端点达到运行状态时,它会向您发送提示。
测试您的推理端点
一旦一切都启动并运行,您将能够看到
- 端点 URL:用于调用端点并向其发送请求
- 游乐场:一种快速测试模型是否工作的小型可视化方式
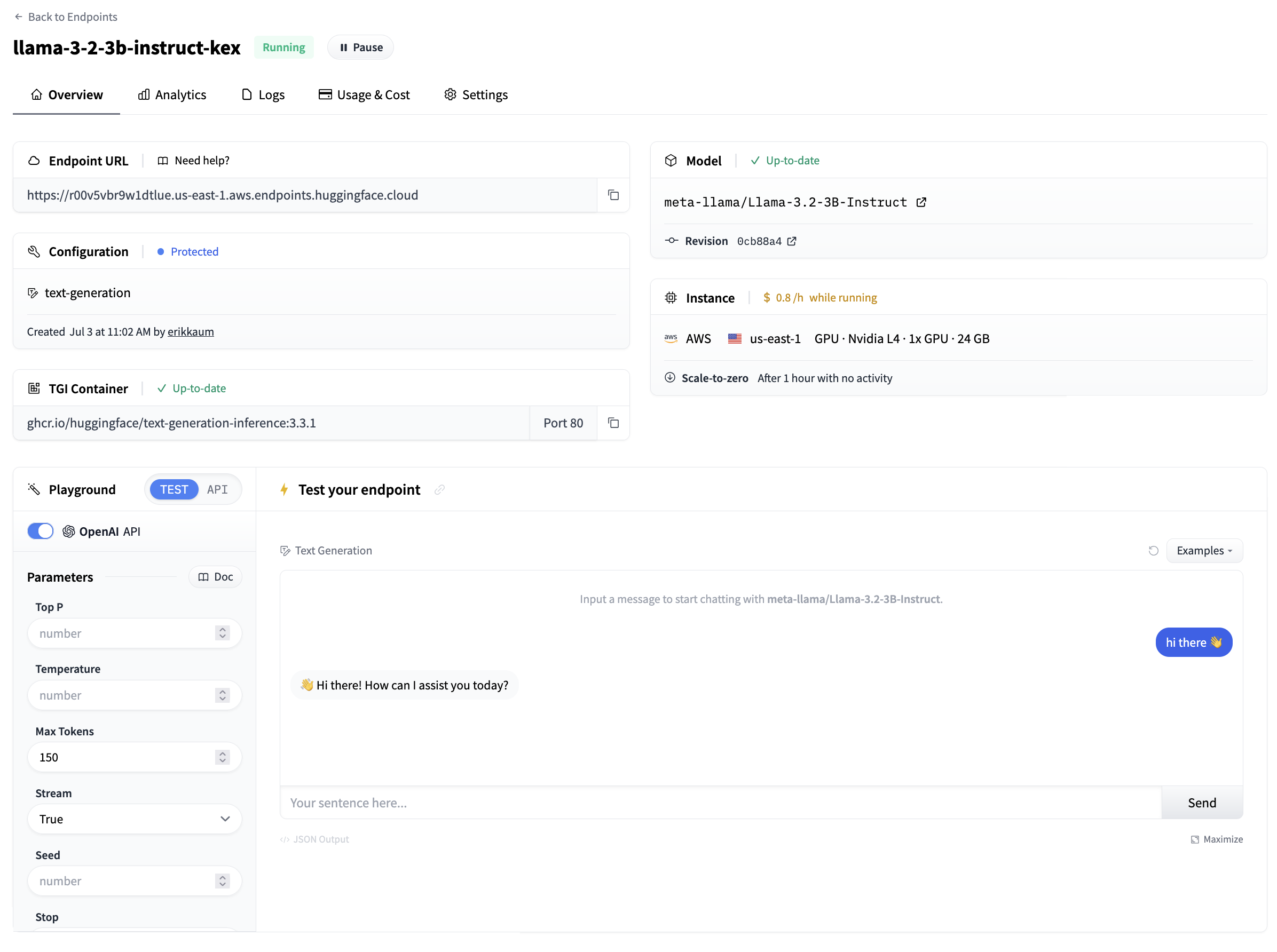
在游乐场侧面,您还可以复制+粘贴调用模型的代码片段。通过单击“应用令牌”,您将被引导到 Hugging Face,配置访问令牌以能够调用模型。默认情况下,所有推理端点都创建为私有端点,需要身份验证,并且所有数据都使用 TLS/SSL 加密传输。
恭喜,您刚刚在推理端点中部署了一个生产就绪型 AI 模型 🔥
测试满意后,您可以暂停推理端点,删除它。或者,如果您不进行操作,它将在 1 小时后缩减为零。
< > 在 GitHub 上更新