推理端点(专用)文档
vLLM
加入 Hugging Face 社区
并获得增强的文档体验
开始使用
vLLM
vLLM 是一款高性能、内存高效的开源大型语言模型推理引擎。它提供高效的调度、KV 缓存处理、批处理和解码功能,所有这些都封装在一个生产就绪的服务器中。对于大多数用例,TGI、vLLM 和 SGLang 将是同等优秀的选择。
核心功能:
- 用于内存效率的 PagedAttention
- 连续批处理
- 优化的 CUDA/HIP 执行
- 推测解码与分块预填充
- 多后端和硬件支持:可在 NVIDIA、AMD 和 AWS Neuron 等平台上运行
配置
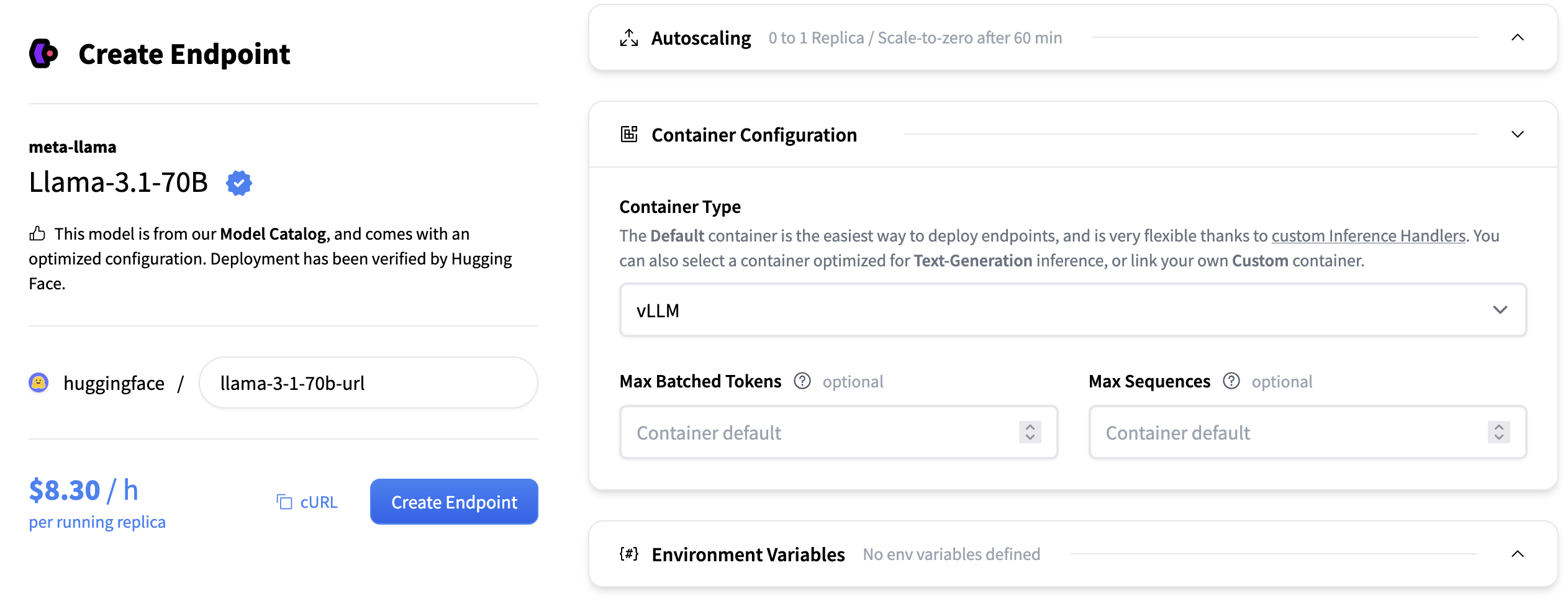
- 最大序列数:单个批次中可同时处理的最大序列(请求)数。它通过序列计数控制批次大小,影响吞吐量和内存使用。例如,如果 max_num_seqs=8,则可以同时处理多达 8 个不同的提示,无论它们的单独长度如何,只要总令牌计数也符合最大批处理令牌数。
- 最大批处理令牌数:单个批次中可处理的最大总令牌数(所有序列的总和)。它通过令牌计数限制批次大小,平衡吞吐量和 GPU 内存分配。
- 张量并行大小:模型权重在每个层内分割的 GPU 数量。增加此值可运行更大的模型并释放 GPU 内存用于 KV 缓存,但可能会引入同步开销。
- KV 缓存数据类型:用于在生成过程中存储键值缓存的数据类型。选项包括“auto”、“fp8”、“fp8_e5m2”和“fp8_e4m3”。使用较低精度类型可以减少内存使用,但可能会略微影响生成质量。
对于更高级的配置,您可以将 vLLM 支持的任何引擎参数作为容器参数传递。例如,将enable_lora更改为true将如下所示

支持的模型
vLLM 对大型语言模型和嵌入模型提供广泛支持。我们建议阅读 vLLM 文档中的支持的模型部分以获取完整列表。
vLLM 还支持 Transformers 中可用的模型实现。目前并非所有模型都支持,但计划支持大多数解码器语言模型和视觉语言模型。
参考资料
我们还建议阅读vLLM 文档以获取更深入的信息。
< > 在 GitHub 上更新