推理端点(专用)文档
文本生成推理 (TGI)
加入 Hugging Face 社区
并获得增强的文档体验
开始使用
文本生成推理 (TGI)
TGI 是一个用 Rust 和 Python 构建的生产级推理引擎,旨在为开源 LLM(例如 LLaMA、Falcon、StarCoder、BLOOM 等)提供高性能服务。使 TGI 成为一个好选择的核心功能是:
- 连续批处理 + 流式传输:通过服务器发送事件 (SSE) 动态分组进行中的请求并流式传输令牌
- 优化注意力与解码:TGI 使用 Flash Attention、Paged Attention、KV 缓存和自定义 CUDA 内核来提高延迟和内存效率
- 量化与权重加载速度:支持 bitsandbytes 和 GPTQ 等量化方法,并使用 Safetensors 减少加载时间
- 生产就绪:完全兼容 OpenAI 的
/v1/chat或/v1/completionsAPI、Prometheus 指标、OpenTelemetry 跟踪、水印、逻辑控制、JSON schema 指导
默认情况下,TGI 版本将是最新可用的版本(可能会有一些延迟)。但您也可以通过更改容器 URL 来指定不同的版本
配置
当选择要部署的模型时,推理端点 UI 会自动检查模型是否受 TGI 支持。如果支持,您将在“容器配置”下看到此选项,您可以在其中更改以下设置:
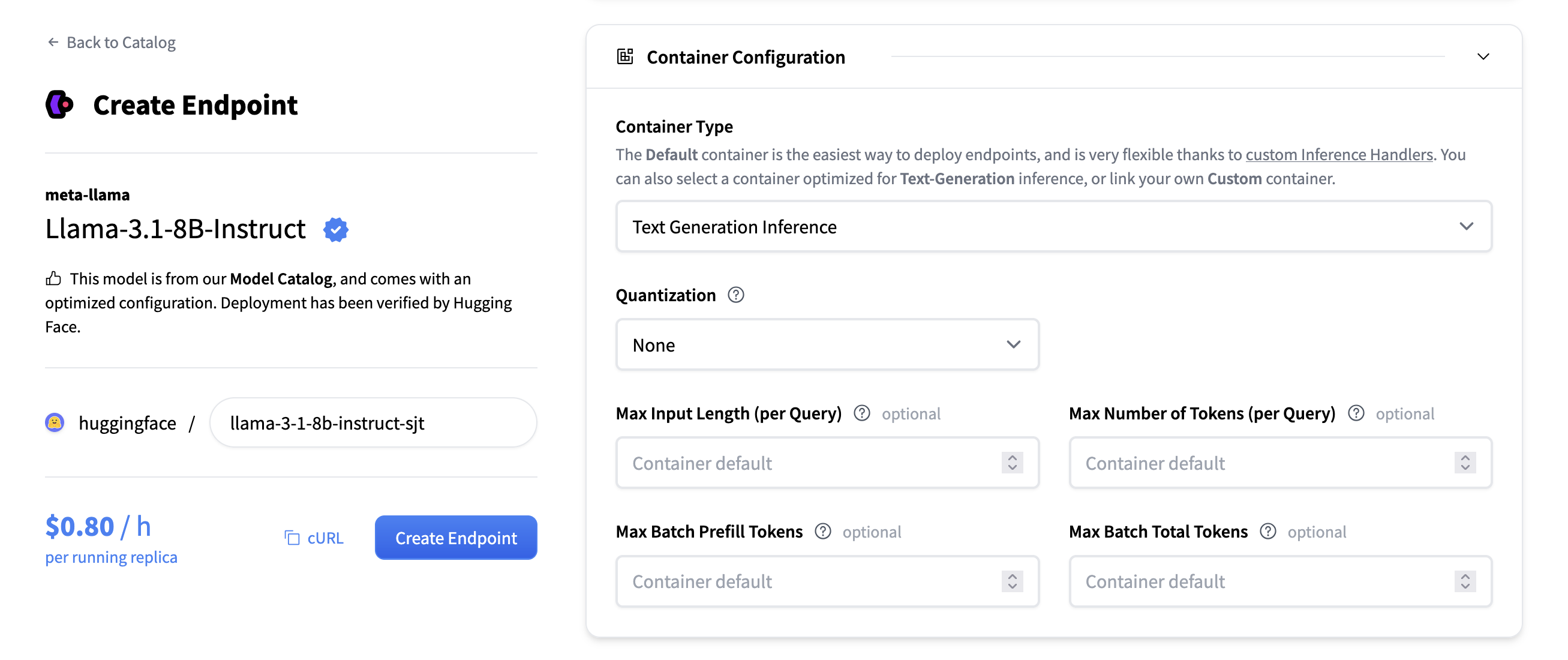
- 量化:模型要使用的量化方法(如果有)。
- 最大令牌数(每个查询):更改请求可包含的最大令牌数。例如,
1512的值表示用户可以发送1000个令牌的提示并生成512个新令牌,或者发送1个令牌的提示并生成1511个新令牌。此值越大,每个请求在 RAM 中占用的空间越大,批处理效果越差。 - 最大输入令牌数(每个查询):最大输入令牌数,即提示中的令牌数。
- 最大批预填充令牌数:限制预填充操作的令牌数。预填充令牌是随用户提示一起发送的令牌。
- 最大批总令牌数:这将更改批处理中潜在令牌的总量。结合“最大令牌数”,这决定了您可以同时服务的并发请求数。如果您将“最大令牌数”设置为 100,并将“最大批总令牌数”也设置为 100,则一次只能服务一个请求。
通常建议在大多数情况下使用零配置(见下文)。TGI 支持其他几个配置参数,您可以在 TGI 文档中找到完整的列表。所有这些都可以通过将值作为环境变量传递给容器来设置,链接到指南。
零配置
TGI v3 中引入的零配置模式可帮助您充分利用硬件,而无需手动配置和反复试验。如果将值留空,TGI 将在服务器启动时自动(根据运行的硬件)为最大输入长度、最大令牌数、最大批预填充令牌数和最大批总令牌数选择最大可能值。这意味着您将充分利用硬件容量。
请注意,有一个注意事项:假设您正在部署 `meta-llama/Llama-3.3-70B-Instruct`,其上下文长度为 128k 令牌。但是您使用的 GPU 只能将模型的上下文三次放入内存。因此,如果您想以完整上下文长度提供模型,则只能服务多达 3 个并发请求。在某些情况下,将最大上下文长度降低到 64k 令牌是可以的,这将允许服务器处理 6 个并发请求。您可以通过将最大输入长度设置为 64k,然后让 TGI 自动配置其余部分来配置此项。
支持的模型
您可以在以下位置找到 TGI 支持的模型:
- 在 Hugging Face Hub 上浏览支持的模型
- 在 TGI 文档的支持模型部分
- 在 推理端点目录中选择热门模型
如果模型受 TGI 支持,推理端点 UI 将通过启用/禁用“容器类型”配置下的选择来指示此情况。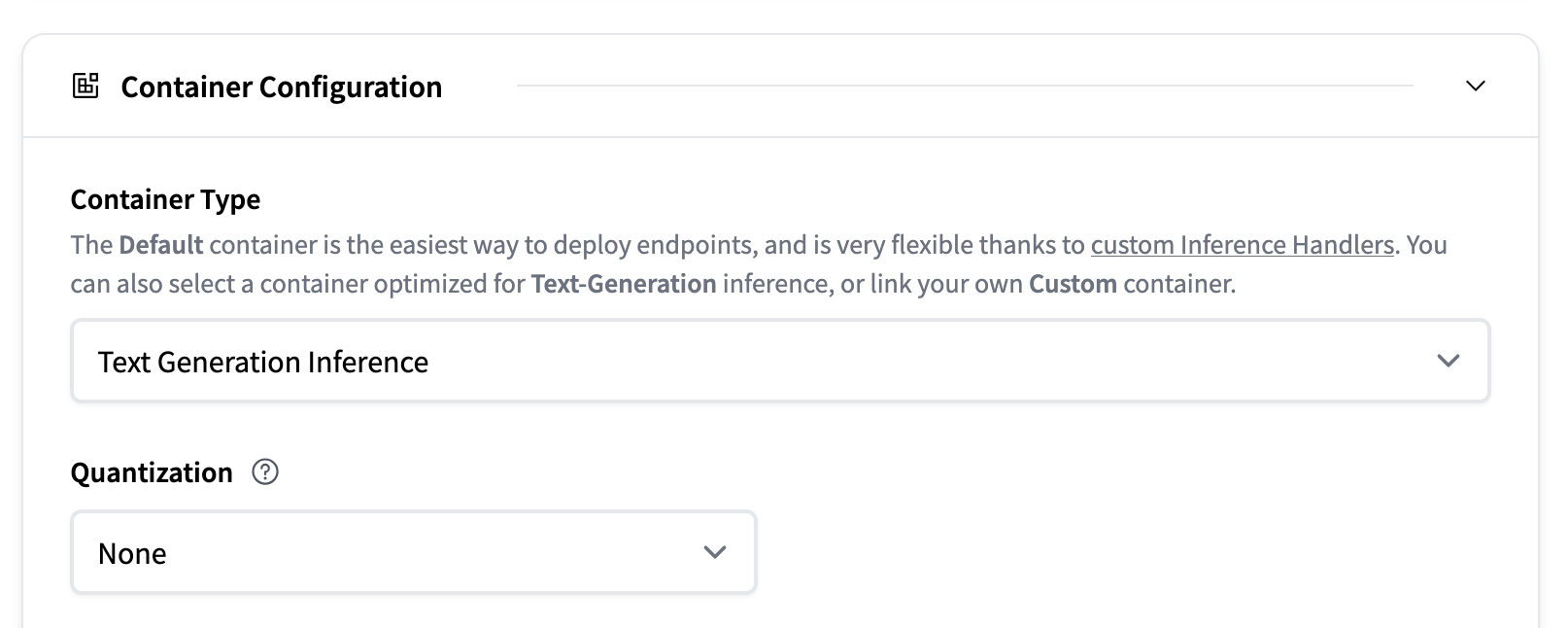
参考资料
我们还建议阅读 TGI 文档,以获取更深入的信息。
< > 在 GitHub 上更新