推理端点(专用)文档
自动扩缩
并获得增强的文档体验
开始使用
自动扩缩
自动扩缩允许您根据流量和硬件利用率动态调整运行模型的端点副本数量。通过利用自动扩缩,您可以无缝处理不同的工作负载,同时优化成本并确保高可用性。
您可以在推理端点卡的“设置”选项卡下找到端点的自动扩缩设置。
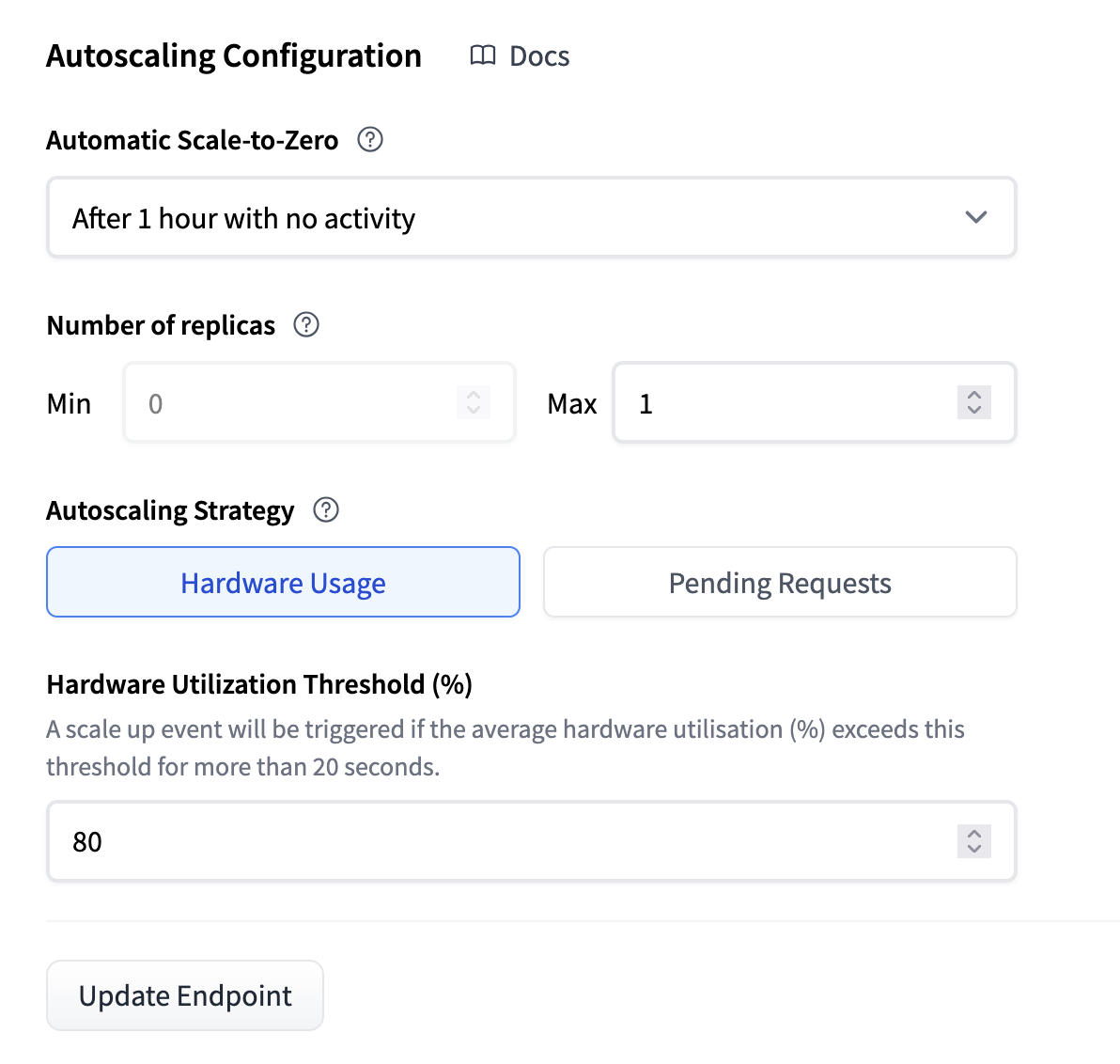
缩减到零
缩减到零意味着您的推理端点在给定持续时间(默认为 1 小时)不活动后将进入空闲状态。当您想优化低成本或工作负载是间歇性时,这通常非常有用。
将副本数量缩减到零有助于通过最大限度地减少非活动期间的资源使用来优化成本节约。然而,重要的是要意识到,当端点收到新请求时,缩减到零意味着存在冷启动期。此外,当新副本初始化时,代理将以状态码 503 响应。为了可能避免这种情况,您还可以将“X-Scale-Up-Timeout”标头添加到您的请求中。这意味着当端点正在扩缩时,代理将保持请求,直到副本准备就绪,或者在指定秒数后超时。例如,“X-Scale-Up-Timeout: 600”将等待 600 秒。
副本数量
通过此设置,您可以更改副本的最大和最小数量。这意味着您可以控制成本的上限和下限。通常,您会将最小值设置为一个值,以便在流量最低时,您仍然能够以可接受的速度为用户提供服务。而最大值则设置为一个值,以便您在预算范围内,即使在流量高峰期也能为用户提供服务。
自动扩缩策略
为了使自动扩缩系统良好运行,需要有一个信号来指示何时扩缩和缩减。为此,我们有两种策略。
基于硬件利用率的扩缩
自动扩缩过程根据硬件利用率指标触发。扩缩标准因所使用的加速器类型而异。
- CPU:当所有副本的平均 CPU 利用率达到阈值(默认为 80%)时,将添加新副本。
- GPU:当所有副本在 1 分钟窗口内的平均 GPU 利用率达到阈值(默认为 80%)时,将添加新副本。
重要的是要注意,扩缩过程每分钟进行一次,缩减过程每 2 分钟进行一次。此频率确保了自动扩缩系统的响应能力和稳定性之间的平衡,并在缩减后有 300 秒的稳定时间。
您还可以在“分析”选项卡中跟踪硬件利用率指标,或在此处阅读更多相关信息。
基于待处理请求的扩缩(Beta 功能)
在某些情况下,硬件利用率指标不够“快速”。原因是硬件指标总是比实际请求略滞后。待处理请求是一个更具前瞻性的指标。
- 待处理请求是指尚未收到 HTTP 状态的请求,这意味着它们包括正在处理的请求和正在进行中的请求。
- 默认情况下,如果在过去 20 秒内每个副本有超过 1.5 个待处理请求,则会触发自动扩缩事件并向您的部署添加一个副本。您可以根据您的特定要求在端点设置中调整此阈值。
与硬件指标类似,您可以在“分析”选项卡中跟踪待处理请求,或在此处阅读更多相关信息。
< > 在 GitHub 上更新