推理端点(专用)文档
配置
加入 Hugging Face 社区
并获得增强的文档体验
开始使用
配置
本节描述了创建新推理端点时可用的配置选项。界面的每个部分都允许对模型如何部署、访问和扩展进行精细控制。
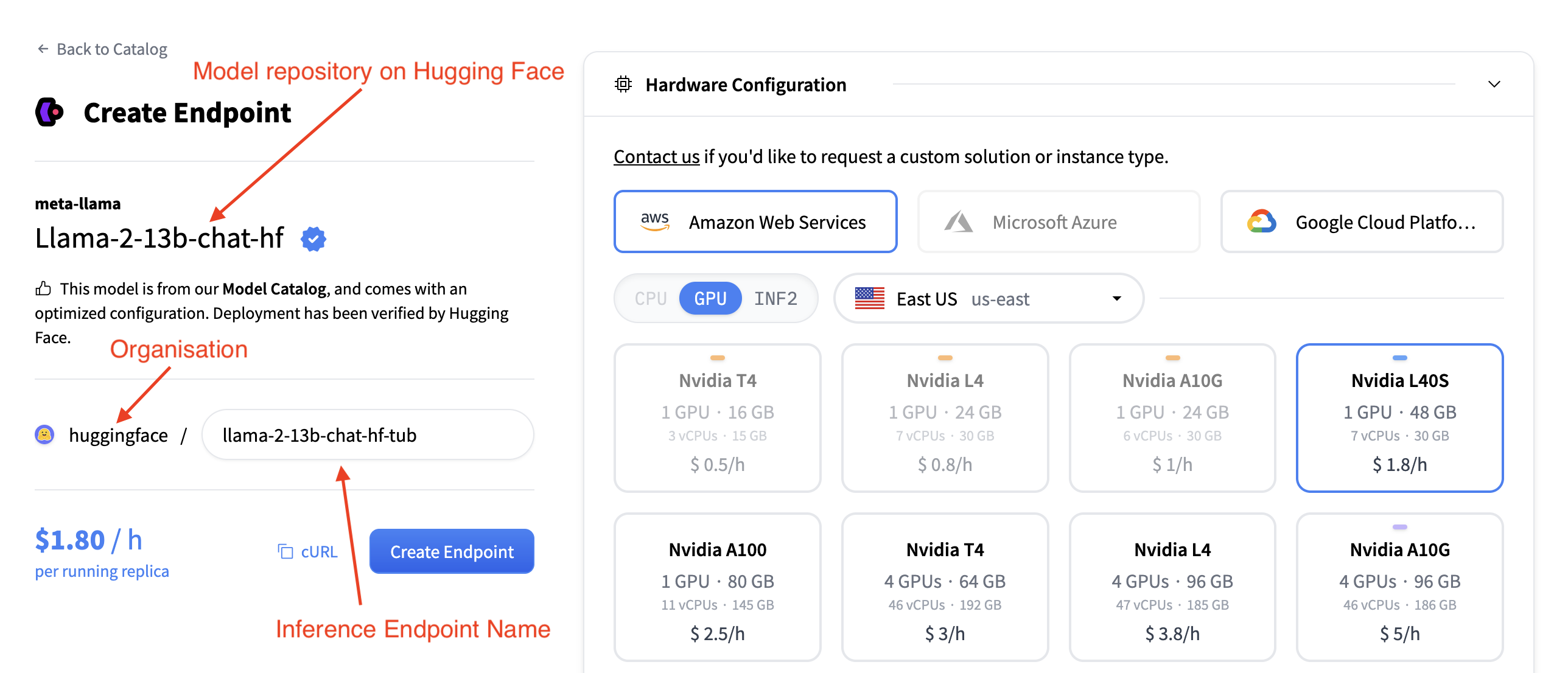
端点名称、模型和组织
在左上角您可以
- 更改推理端点名称
- 验证您将此模型部署到哪个组织
- 验证您正在部署哪个模型
- 以及您正在从哪个 Hugging Face Hub 仓库部署此模型
硬件配置
硬件配置部分允许您选择用于托管模型的计算后端。您可以从三个主要云提供商中进行选择:
- 亚马逊网络服务 (AWS)
- Microsoft Azure
- 谷歌云平台
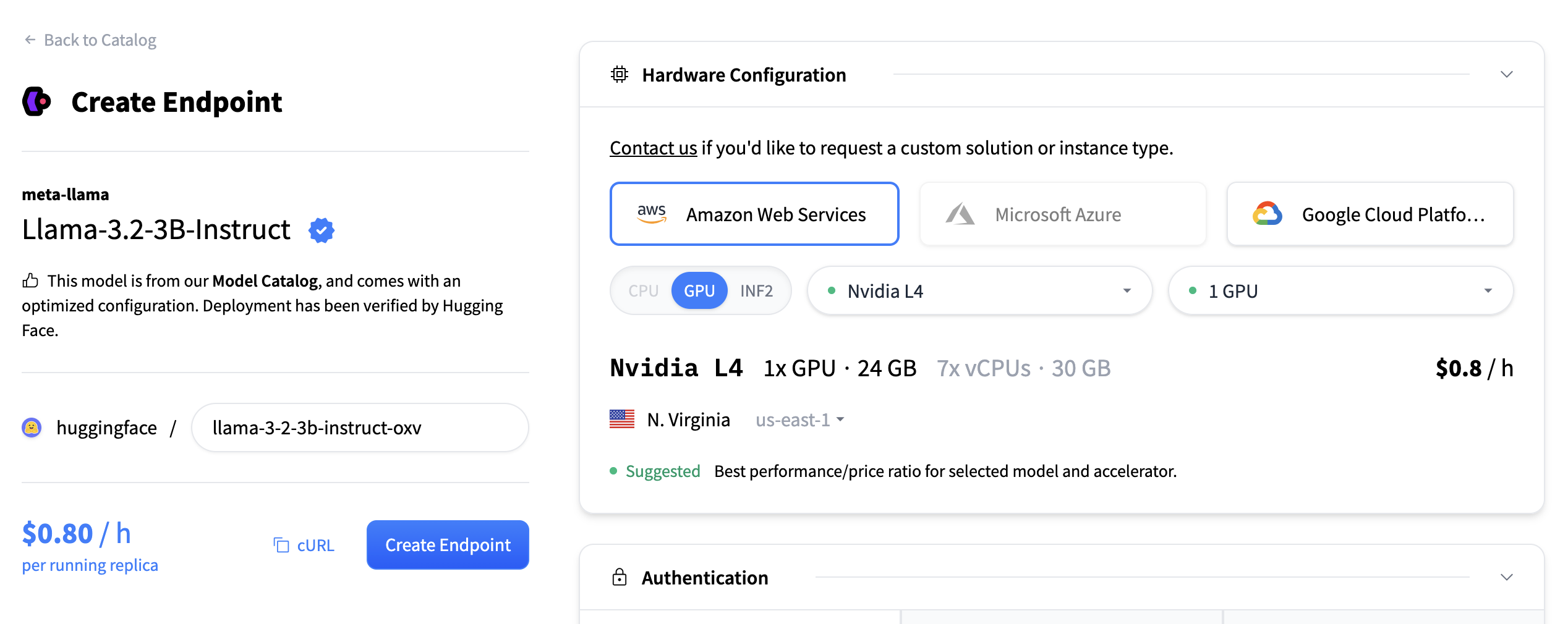
您还必须选择加速器类型
- CPU
- GPU
- INF2 (AWS Inferentia)
此外,您可以使用下拉菜单选择部署区域(例如,美国东部)。选择提供商、加速器和区域后,将显示可用实例类型的列表。每个实例磁贴包括
- GPU 类型和数量
- 内存(例如,48 GB)
- vCPU 和 RAM
- 每小时定价(例如,$1.80/小时)
您可以选择一个磁贴来为您的部署选择该实例类型。在选定区域中不兼容或不可用的实例将变灰且不可点击。
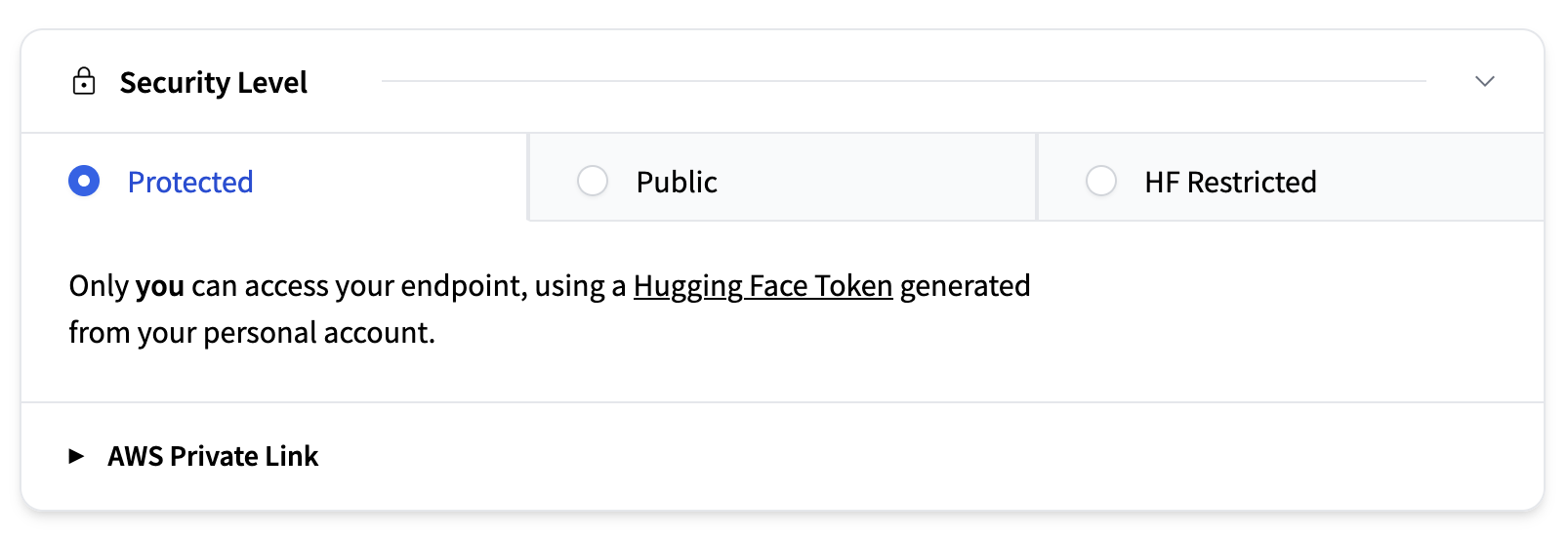
安全级别
本节确定谁可以访问您部署的端点。可用选项包括
- 受保护(默认):仅供您的 Hugging Face 组织成员使用个人访问令牌访问。端点通过 TLS/SSL 进行保护。
- 公开:互联网上的任何人都可以访问该端点。
- HF 受限:任何拥有 Hugging Face 账户的人都可以通过其账户生成的个人 Hugging Face 令牌访问。
- AWS 私有:端点仅通过区域内安全的 AWS PrivateLink 连接可用。
自动扩缩
自动扩缩部分配置了您的模型运行的副本数量,以及系统是否在不活动期间缩减到零。有关更多信息,我们建议阅读自动扩缩的深入指南。
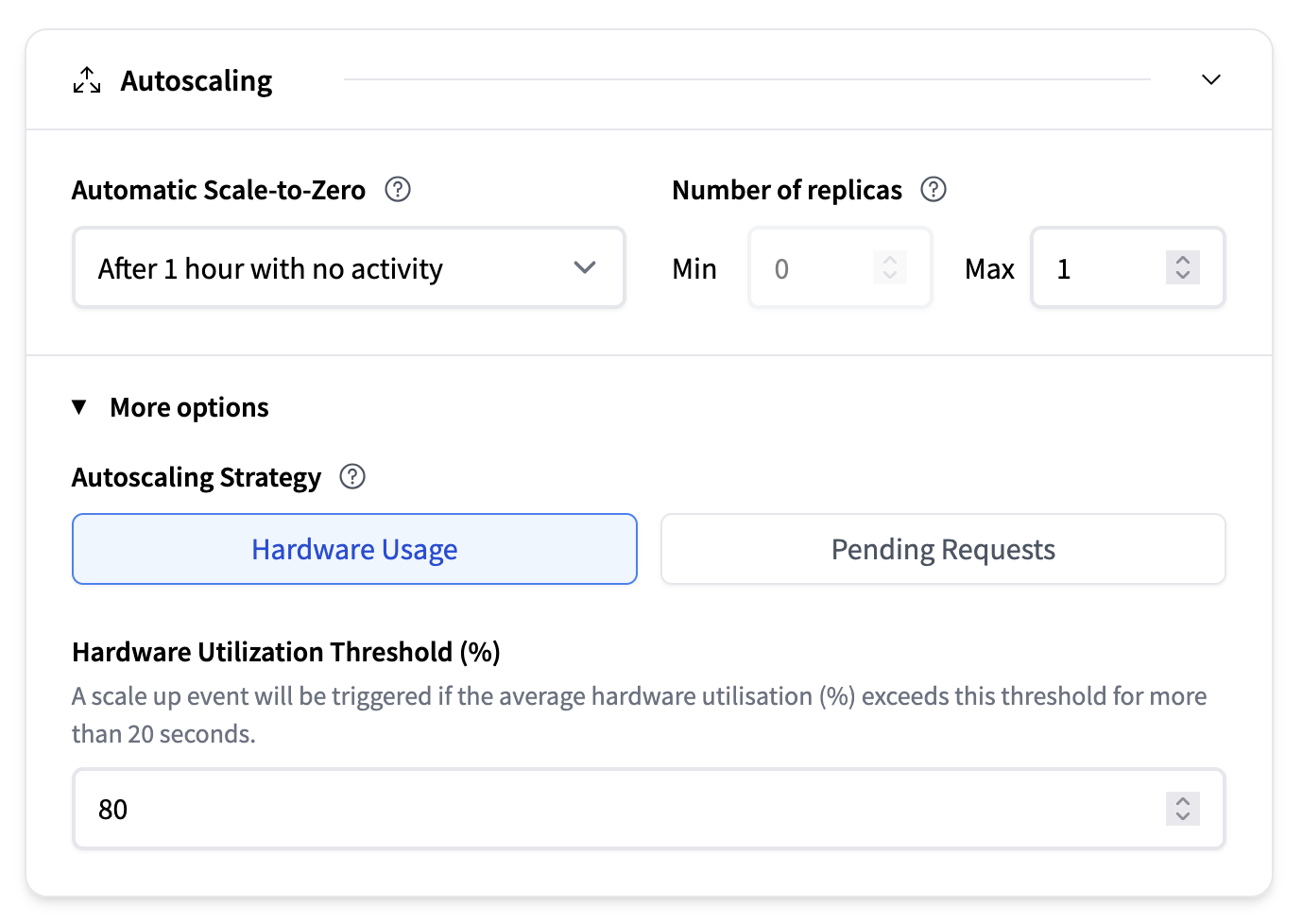
- 自动缩减到零:一个下拉菜单让您可以选择系统在最后一次请求后应等待多长时间才能缩减到零。默认值为无活动 1 小时后。
- 副本数量:
- 最小值:保持运行的最小副本数量。请注意,启用自动缩减到零要求将其设置为 0。
- 最大值:允许的最大副本数量(例如,1)
- 自动扩缩策略:
- 基于硬件使用率:例如,如果平均硬件利用率 (%) 超过此阈值超过 20 秒,将触发扩缩事件。
- 待处理请求:如果待处理请求的平均数量超过此阈值超过 20 秒,将触发扩缩事件。
容器配置
本节允许您指定托管模型的容器行为方式。此设置取决于所选的推理引擎。有关配置详细信息,请阅读推理引擎部分。
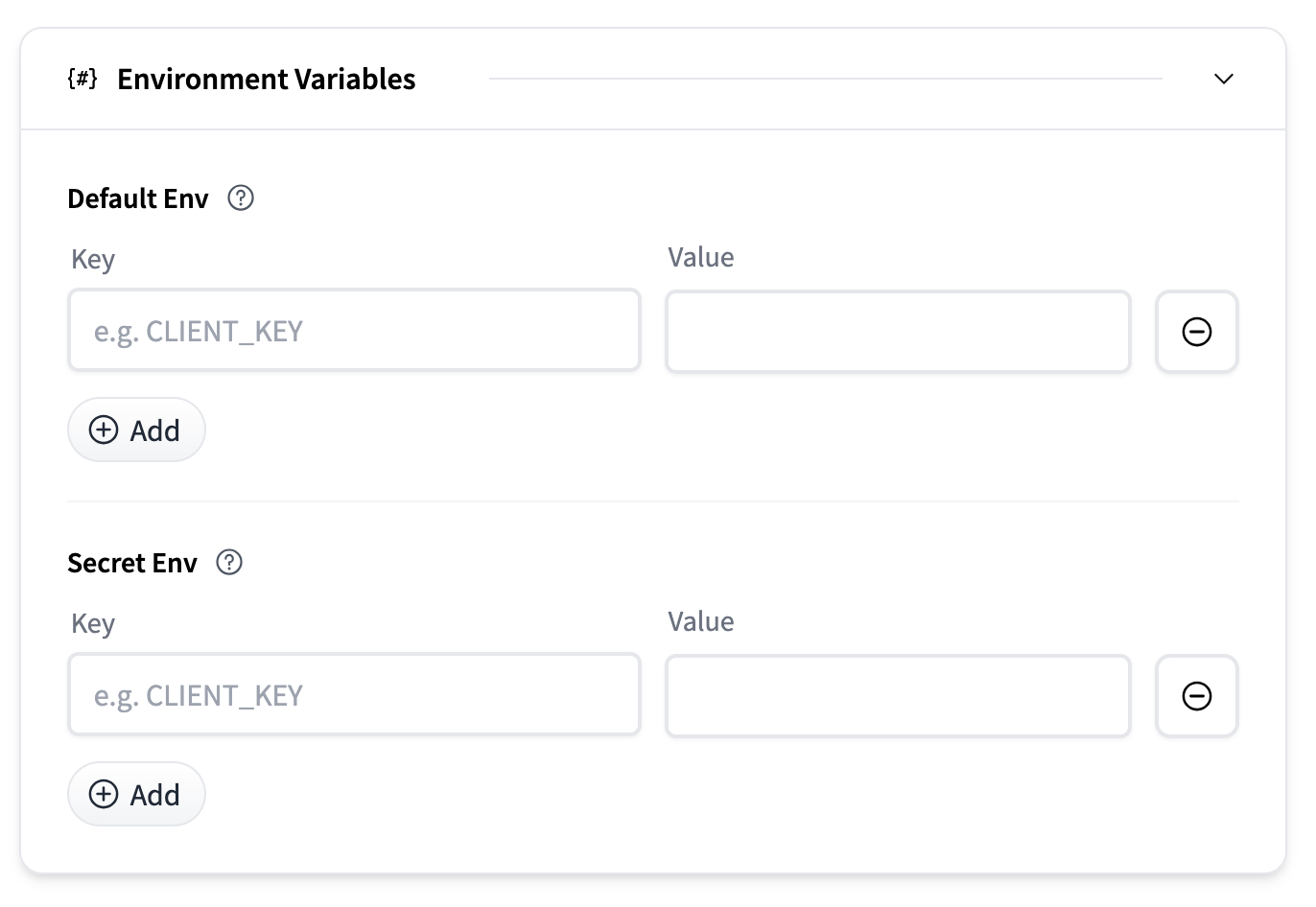
环境变量
可以提供环境变量来自定义容器行为或传递秘密。
- 默认环境变量:作为普通环境变量传递的键值对。
- 秘密环境变量:安全存储并在运行时注入的键值对。
每个部分都允许您使用“添加”按钮添加多个条目。
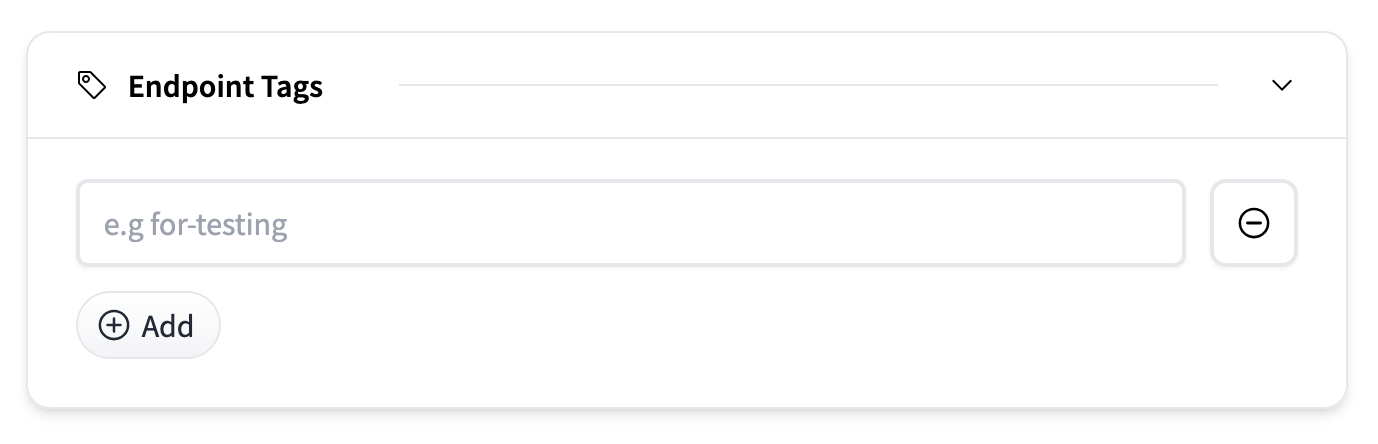
端点标签
您可以使用标签(例如,用于测试)标记端点,以帮助跨环境或团队组织和管理部署。在仪表板中,您将能够根据这些标签过滤和排序端点。标签是通过“添加”按钮添加的纯文本标签。
高级设置
高级设置提供了对部署更精细的控制。
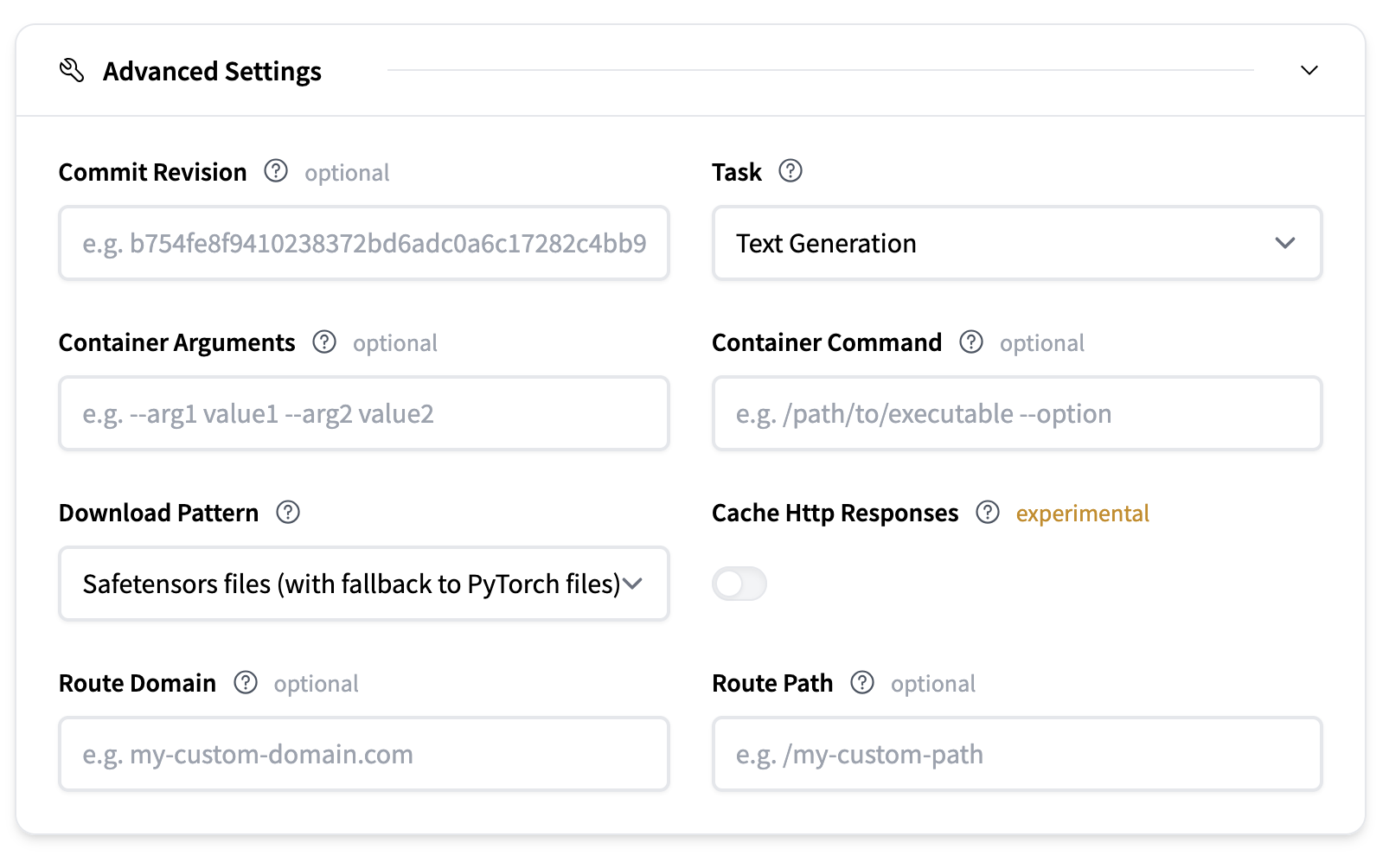
- 提交修订:可选地指定一个提交哈希,以确定您要从 Hugging Face Hub 上的模型仓库下载哪个修订的模型工件。
- 任务:定义模型任务的类型。这通常从模型仓库推断。
- 容器参数:向容器入口点传递 CLI 样式参数。
- 容器命令:完全覆盖容器入口点。
- 下载模式:定义要下载的模型文件。