推理端点(专用)文档
分析和指标
并获得增强的文档体验
开始使用
分析和指标
“分析”页面就像是您已部署模型的控制中心。它会实时显示运行情况、调用模型的用户数量、硬件使用情况、延迟等信息。本文档将深入探讨每个指标的含义以及如何分析图表。
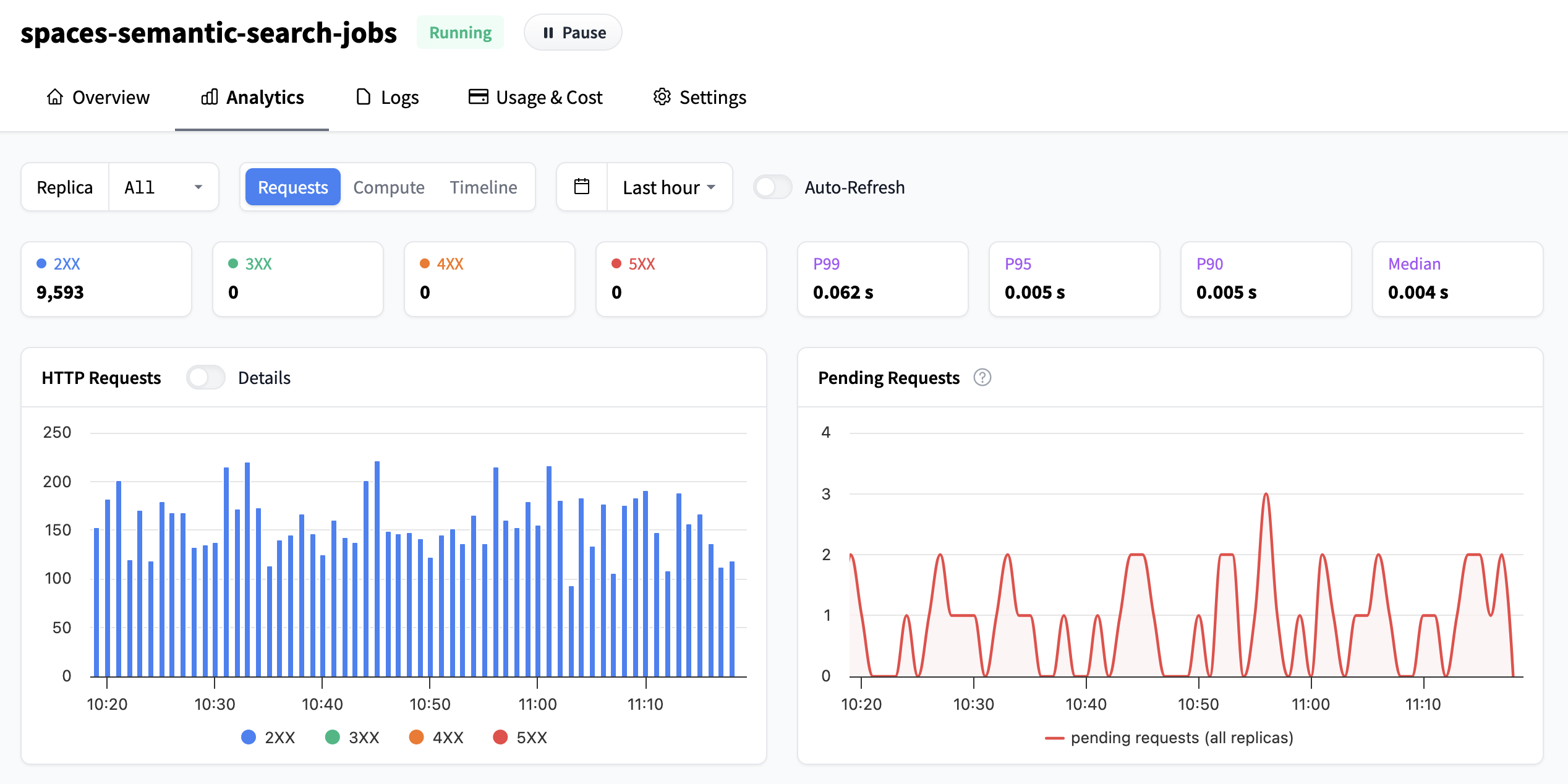
在顶部栏中,您可以配置查看指标的时间范围,此设置会影响页面上的所有图表。您可以从下拉列表中选择任何现有设置,或在任何图表上点击并拖动以设置自定义时间范围。您还可以启用/禁用自动刷新,或按副本或全部查看指标。

理解图表
请求数量
左上角的第一个图表显示您的推理端点收到的请求数量。默认情况下,它们按 HTTP 响应类别分组,但通过切换开关,您可以按单独的状态查看它们。温馨提示,HTTP 响应类别有:
- 信息性响应 (100-199):服务器已收到您的请求并正在处理。例如,
102 Processing表示服务器仍在处理您的请求。 - 成功响应 (200-299):您的请求已成功接收并完成。例如,
200 OK表示一切正常。 - 重定向消息 (300-399):服务器告诉您的客户端在其他地方查找信息或采取其他操作。例如,
301 Moved Permanently表示资源已有了新地址。 - 客户端错误响应 (400-499):您的客户端发送的请求有问题(例如 URL 中的拼写错误或缺少数据)。例如,
404 Not Found表示服务器找不到您请求的内容。 - 服务器错误响应 (500-599):服务器在尝试处理您的请求时遇到问题。例如,
502 Bad Gateway表示服务器从它尝试联系的另一个服务器收到了无效响应。
我们建议查阅 MDN web docs 以获取有关单个状态码的更多信息。
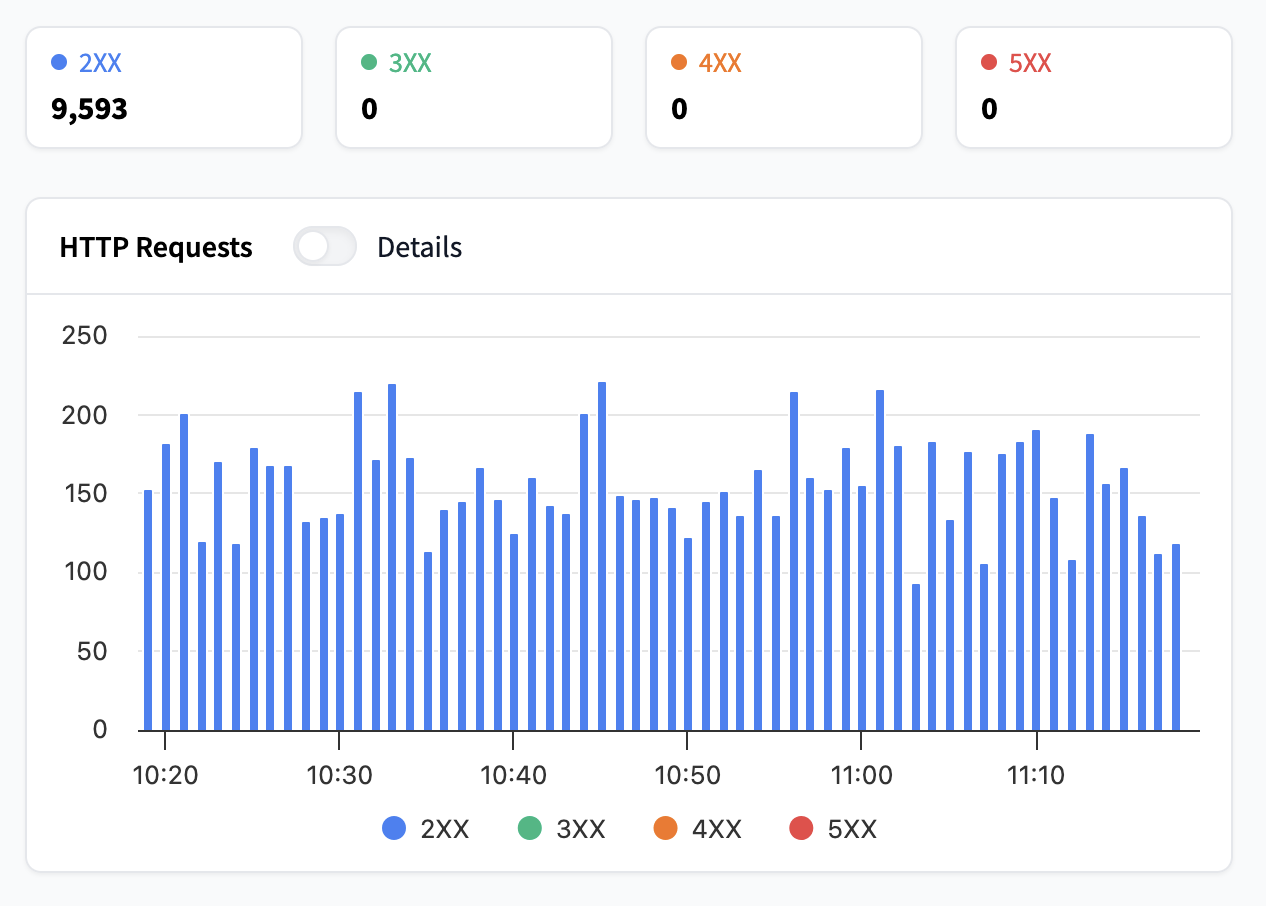
待处理请求
待处理请求是指尚未收到 HTTP 状态的请求,这意味着它们包括正在进行中的请求和当前正在处理的请求。如果此指标增加过多,则表示您的请求正在排队,并且您的用户必须等待请求完成。在这种情况下,您应该考虑增加副本数量或使用自动扩缩,您可以在自动扩缩指南中阅读更多相关信息
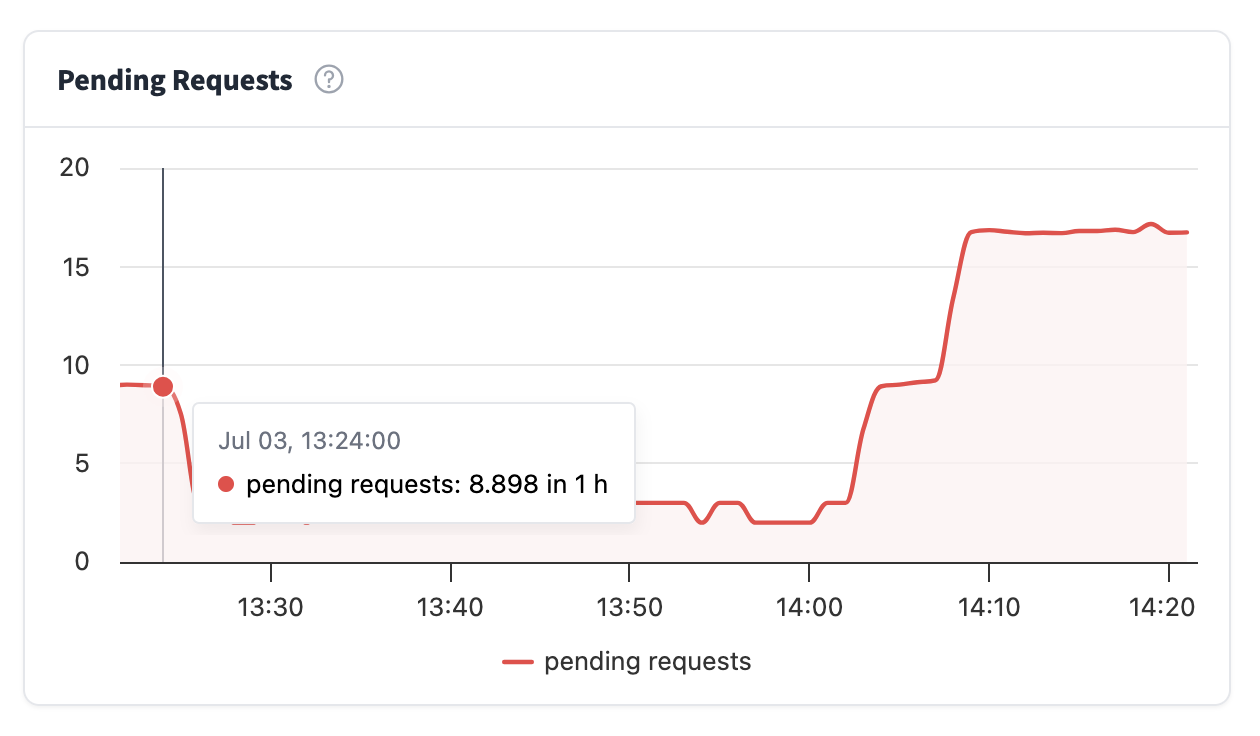
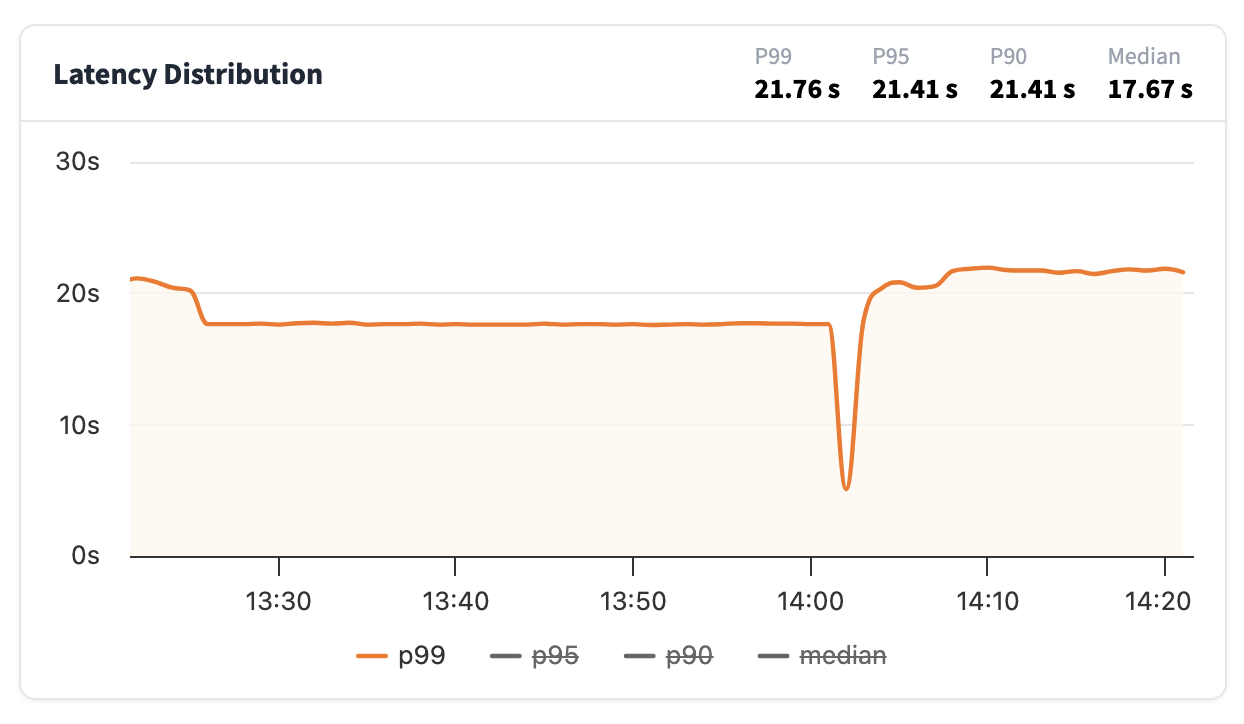
延迟分布
从该图表您可以查看推理端点生成响应所需的时间。延迟报告如下:
- p99:表示 99% 的请求快于此值
- p95:表示 95% 的请求快于此值
- p90:表示 90% 的请求快于此值
- 中位数:表示 50% 的请求快于此值
通常,一个好的指标是查看中位数和 p99 之间的差异有多大。值越接近,延迟越均匀;如果差异很大,则表示您的推理端点用户通常响应速度很快,但最坏情况下的延迟可能会很长。
副本状态
在副本状态图中,您将在基本视图中看到在某个时间点有多少个正在运行的副本。红线显示了您当前的最大副本设置。

如果您切换高级设置,您将看到各个副本的不同状态,从“待处理”一直到“正在运行”。这对于了解端点实际准备好服务请求所需的时间非常有用。

硬件使用情况
最后四个图表专门用于显示硬件使用情况。您会发现:
- CPU 使用率:正在使用的处理能力。
- 内存使用率:正在使用的 RAM 容量。
- GPU 使用率:正在使用的 GPU 处理能力。
- GPU 内存 (VRAM) 使用率:正在使用的 GPU 内存容量。
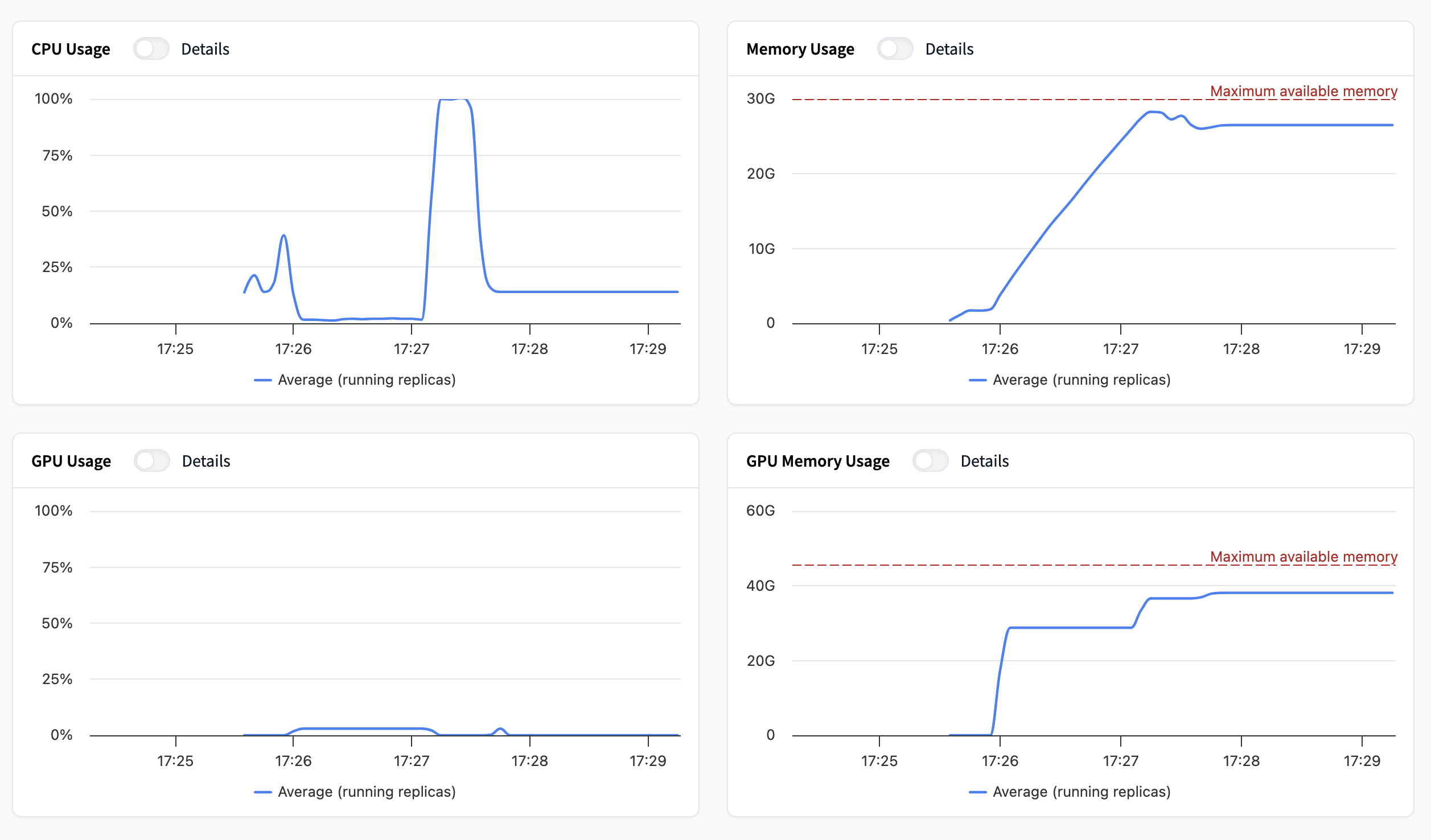
如果您启用了基于硬件利用率的自动扩缩,这些指标将决定您的自动扩缩行为。您可以在此处阅读有关自动扩缩的更多信息。
使用推理端点指标 API 创建集成
此功能目前处于 Beta 阶段。您需要订阅企业版才能使用此功能。
您能够将您的推理端点指标集成到您的内部工具中。
利用 OpenMetrics,您可以创建集成,以更精细地、几乎实时地查看您的端点指标,例如显示:
- 按副本分组的请求
- 请求的延迟分布
- 所有加速器类型的硬件指标
OpenMetrics 是一种标准化格式,用于表示和传输时间序列数据,使系统更容易消费和处理指标,确保数据结构最适合存储和传输。
可以在您的内部工具中根据这些指标为您的端点设置进一步的配置和通知。
连接您的内部工具
有各种工具可与 OpenMetrics 配合使用。您需要设置一个代理。以下是一些示例文档可帮助您入门:
订阅企业版
您可以随时在 https://huggingface.co/enterprise?subscribe=true 注册企业版计划,起价为 $20/用户/月。如有任何问题或功能请求,请发送电子邮件至 api-enterprise@huggingface.co
< > 在 GitHub 上更新