推理端点(专用)文档
创建您自己的转录应用程序
并获得增强的文档体验
开始使用
创建您自己的转录应用程序
本教程将指导您使用 Hugging Face 推理端点构建一个完整的转录应用程序。我们将创建一个能够转录音频文件并生成带有行动项的智能摘要的应用程序——非常适合会议记录、访谈或任何音频内容。
本教程使用 Python 和 Gradio,但您可以将方法应用于任何可以发出 HTTP 请求的语言。部署在推理端点上的模型使用标准 API,因此您可以将它们集成到 Web 应用程序、移动应用程序或任何其他系统中。
创建转录端点
首先,我们需要为音频转录创建一个推理端点。我们将使用 OpenAI 的 Whisper 模型进行高质量语音识别。
首先导航到 Inference Endpoints UI,登录后您应该会看到一个用于创建新推理端点的按钮。单击“New”按钮。
从那里您将被定向到目录。模型目录包含流行的模型,这些模型已调整配置以实现一键部署。您可以按名称、任务、硬件价格等进行筛选。
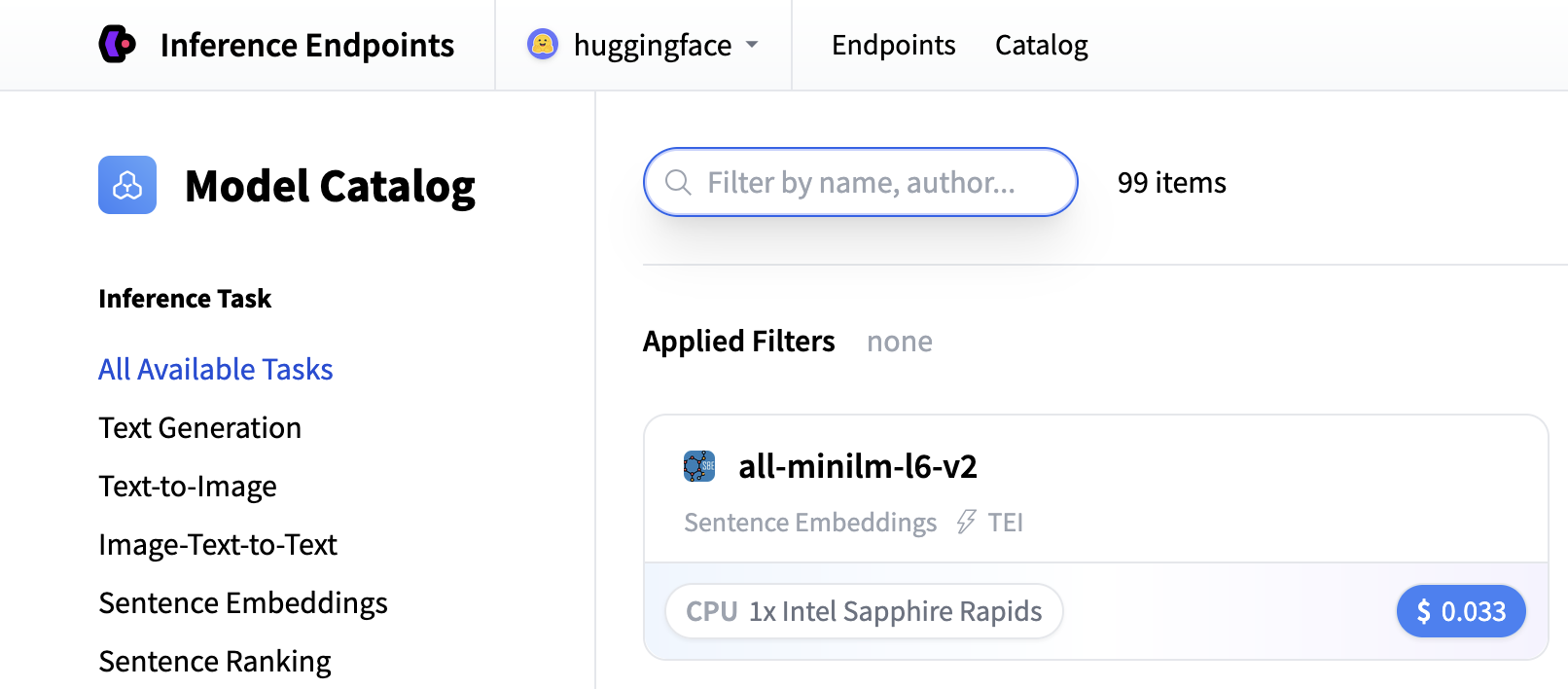
搜索“whisper”以查找转录模型,或者您可以使用 openai/whisper-large-v3 创建自定义端点。此模型为多种语言提供出色的转录质量,并处理各种音频格式。
对于转录模型,我们建议使用
- GPU:NVIDIA L4 或 A10G,用于音频处理,性能良好
- 实例大小:x1(足以满足大多数转录工作负载)
- 自动缩放:启用缩放到零以在使用时节省成本
点击“创建端点”部署您的转录服务。
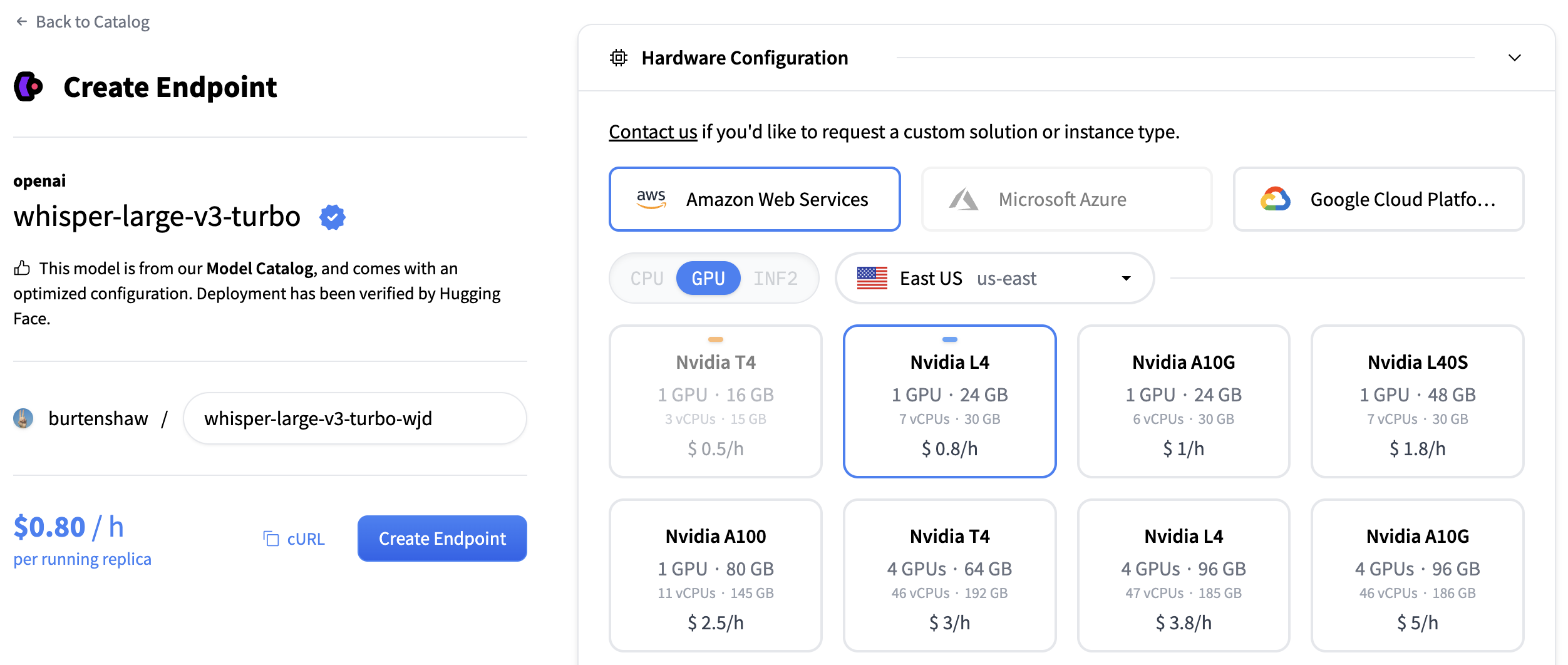
您的端点将需要大约 5 分钟来初始化。一旦准备就绪,您将在“运行中”状态下看到它。
创建文本生成端点
现在我们再次执行相同的操作,但这次是针对文本生成模型。为了生成摘要和行动项,我们将使用 Qwen/Qwen3-1.7B 模型创建第二个端点。
遵循相同的过程
- 点击推理端点 UI 中的“新建”按钮
- 在目录中搜索
qwen3 1.7b - 此模型建议使用 NVIDIA L4 和 x1 实例大小
- 保留默认设置(启用缩放到零,1 小时超时)
- 点击“创建端点”
此模型已针对文本生成任务进行优化,并将提供出色的摘要功能。两个端点都将需要大约 3-5 分钟来初始化。
测试您的端点
一旦您的端点运行起来,您就可以在 playground 中测试它们。转录端点将接受音频文件并返回文本转录。
使用简短的音频样本进行测试,以验证转录质量。
获取您的端点详细信息
您需要从您的端点页面获取端点详细信息。
- 基本 URL:
https://<endpoint-name>.endpoints.huggingface.cloud/v1/ - 模型名称: 您的端点名称
- 令牌: 您从设置获取的 HF 令牌
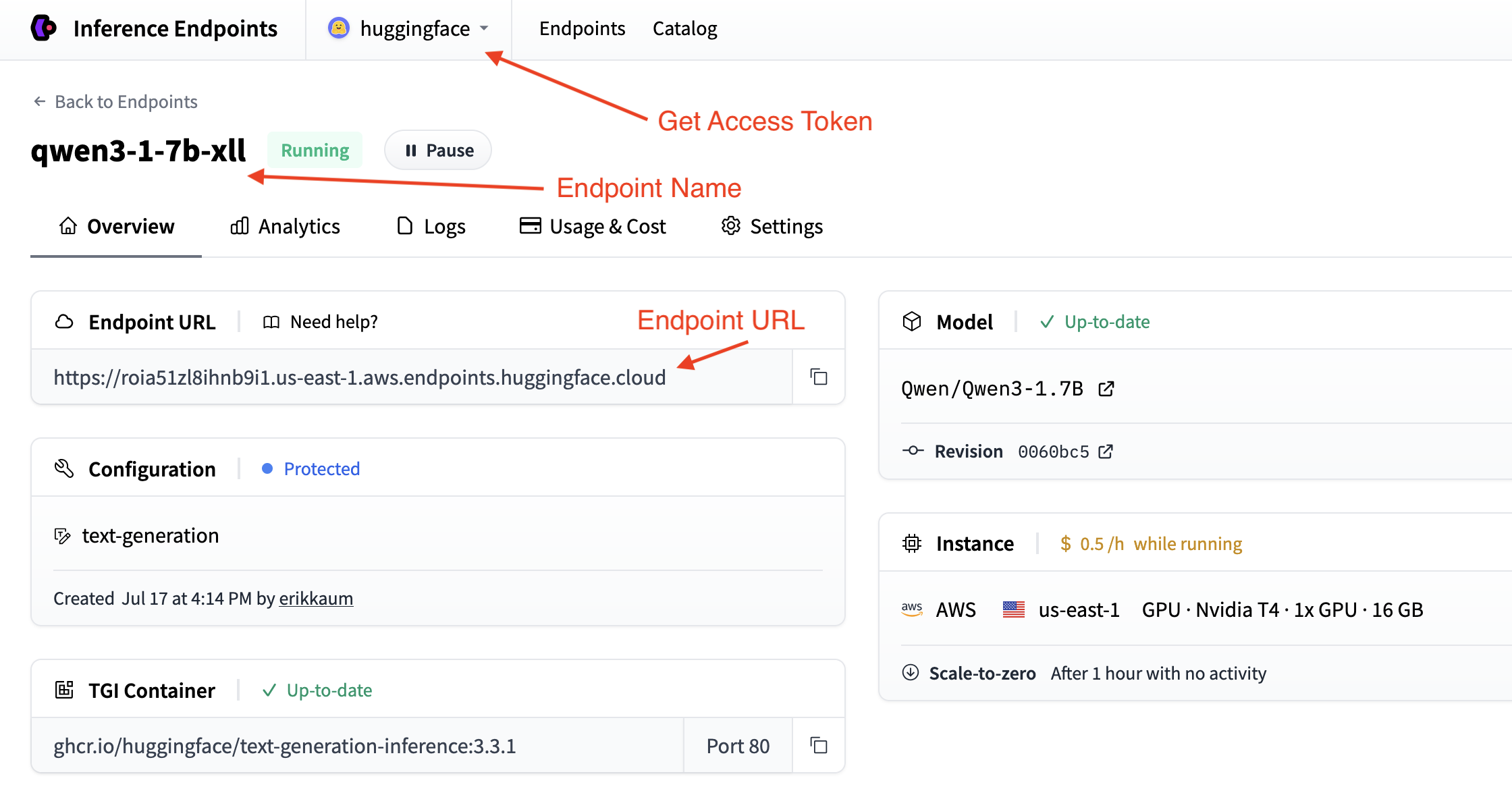
您可以通过在命令行中使用 curl 测试您的端点来验证您的详细信息。
curl "<endpoint-url>" \
-X POST \
--data-binary '@<audio-file>' \
-H "Accept: application/json" \
-H "Content-Type: audio/flac" \构建转录应用程序
现在我们一步步构建一个转录应用程序。我们将它分解成逻辑块,以创建一个完整的解决方案,可以转录音频并生成智能摘要。
步骤 1:设置依赖项和导入
我们将使用 requests 库连接到两个端点,并使用 gradio 创建界面。让我们安装所需的软件包。
pip install gradio requests
然后,在一个新的 Python 文件中设置您的导入。
import os
import gradio as gr
import requests步骤 2:配置您的端点连接
根据您在之前步骤中收集的详细信息,设置连接转录和摘要端点的配置。
# Configuration for both endpoints
TRANSCRIPTION_ENDPOINT = "https://your-whisper-endpoint.endpoints.huggingface.cloud/api/v1/audio/transcriptions"
SUMMARIZATION_ENDPOINT = "https://your-qwen-endpoint.endpoints.huggingface.cloud/v1/chat/completions"
HF_TOKEN = os.getenv("HF_TOKEN") # Your Hugging Face Hub token
# Headers for authentication
headers = {
"Authorization": f"Bearer {HF_TOKEN}"
}您的端点现在已配置为处理音频转录和文本摘要。
您可能还需要使用 os.getenv 来获取您的端点详细信息。
步骤 3:创建转录函数
接下来,我们将创建一个函数来处理音频文件上传和转录
def transcribe_audio(audio_file_path):
"""Transcribe audio using direct requests to the endpoint"""
# Read audio file and prepare for upload
with open(audio_file_path, "rb") as audio_file:
# Read the audio file as binary data and represent it as a file object
files = {"file": audio_file.read()}
# Make the request to the transcription endpoint
response = requests.post(TRANSCRIPTION_ENDPOINT, headers=headers, files=files)
# Check if the request was successful
if response.status_code == 200:
result = response.json()
return result.get("text", "No transcription available")
else:
return f"Error: {response.status_code} - {response.text}"转录端点期望在 files 参数中上传文件。请确保将音频文件读取为二进制数据并正确传递给 API。
步骤 4:创建摘要函数
现在我们将创建一个函数来从转录的文本中生成摘要。我们将进行一些简单的提示工程以获得最佳结果。
def generate_summary(transcript):
"""Generate summary using requests to the chat completions endpoint"""
# define a nice prompt to get the best results for our use case
prompt = f"""
Analyze this meeting transcript and provide:
1. A concise summary of key points
2. Action items with responsible parties
3. Important decisions made
Transcript: {transcript}
Format with clear sections:
## Summary
## Action Items
## Decisions Made
"""
# Prepare the payload using the Messages API format
payload = {
"model": "your-qwen-endpoint-name", # Use the name of your endpoint
"messages": [{"role": "user", "content": prompt}],
"max_tokens": 1000, # we can also set a max_tokens parameter to limit the length of the response
"temperature": 0.7, # we might want to set lower temperature for more deterministic results
"stream": False # we don't need streaming for this use case
}
# Headers for chat completions
chat_headers = {
"Accept": "application/json",
"Content-Type": "application/json",
"Authorization": f"Bearer {HF_TOKEN}"
}
# Make the request
response = requests.post(SUMMARIZATION_ENDPOINT, headers=chat_headers, json=payload)
response.raise_for_status()
# Parse the response
result = response.json()
return result["choices"][0]["message"]["content"]步骤 5:整合所有功能
现在让我们构建 Gradio 界面。我们将使用 gr.Interface 类来创建一个简单的界面,允许我们上传音频文件并查看转录和摘要。
首先,我们将创建一个处理完整工作流程的主处理函数。
def process_meeting_audio(audio_file):
"""Main processing function that handles the complete workflow"""
if audio_file is None:
return "Please upload an audio file.", ""
try:
# Step 1: Transcribe the audio
transcript = transcribe_audio(audio_file)
# Step 2: Generate summary from transcript
summary = generate_summary(transcript)
return transcript, summary
except Exception as e:
return f"Error processing audio: {str(e)}", ""然后,我们可以在 Gradio 界面中运行该函数。我们将添加一些描述和标题,使其更易于用户使用。
# Create Gradio interface
app = gr.Interface(
fn=process_meeting_audio,
inputs=gr.Audio(label="Upload Meeting Audio", type="filepath"),
outputs=[
gr.Textbox(label="Full Transcript", lines=10),
gr.Textbox(label="Meeting Summary", lines=8),
],
title="🎤 AI Meeting Notes",
description="Upload audio to get instant transcripts and summaries.",
)就是这样!您现在可以使用 python app.py 在本地运行应用程序并进行测试。
点击查看完整脚本
import gradio as gr
import os
import requests
# Configuration for both endpoints
TRANSCRIPTION_ENDPOINT = "https://your-whisper-endpoint.endpoints.huggingface.cloud/api/v1/audio/transcriptions"
SUMMARIZATION_ENDPOINT = "https://your-qwen-endpoint.endpoints.huggingface.cloud/v1/chat/completions"
HF_TOKEN = os.getenv("HF_TOKEN") # Your Hugging Face Hub token
# Headers for authentication
headers = {
"Authorization": f"Bearer {HF_TOKEN}"
}
def transcribe_audio(audio_file_path):
"""Transcribe audio using direct requests to the endpoint"""
# Read audio file and prepare for upload
with open(audio_file_path, "rb") as audio_file:
files = {"file": audio_file.read()}
# Make the request to the transcription endpoint
response = requests.post(TRANSCRIPTION_ENDPOINT, headers=headers, files=files)
if response.status_code == 200:
result = response.json()
return result.get("text", "No transcription available")
else:
return f"Error: {response.status_code} - {response.text}"
def generate_summary(transcript):
"""Generate summary using requests to the chat completions endpoint"""
prompt = f"""
Analyze this meeting transcript and provide:
1. A concise summary of key points
2. Action items with responsible parties
3. Important decisions made
Transcript: {transcript}
Format with clear sections:
## Summary
## Action Items
## Decisions Made
"""
# Prepare the payload using the Messages API format
payload = {
"model": "your-qwen-endpoint-name", # Use the name of your endpoint
"messages": [{"role": "user", "content": prompt}],
"max_tokens": 1000,
"temperature": 0.7,
"stream": False
}
# Headers for chat completions
chat_headers = {
"Accept": "application/json",
"Content-Type": "application/json",
"Authorization": f"Bearer {HF_TOKEN}"
}
# Make the request
response = requests.post(SUMMARIZATION_ENDPOINT, headers=chat_headers, json=payload)
response.raise_for_status()
# Parse the response
result = response.json()
return result["choices"][0]["message"]["content"]
def process_meeting_audio(audio_file):
"""Main processing function that handles the complete workflow"""
if audio_file is None:
return "Please upload an audio file.", ""
try:
# Step 1: Transcribe the audio
transcript = transcribe_audio(audio_file)
# Step 2: Generate summary from transcript
summary = generate_summary(transcript)
return transcript, summary
except Exception as e:
return f"Error processing audio: {str(e)}", ""
# Create Gradio interface
app = gr.Interface(
fn=process_meeting_audio,
inputs=gr.Audio(label="Upload Meeting Audio", type="filepath"),
outputs=[
gr.Textbox(label="Full Transcript", lines=10),
gr.Textbox(label="Meeting Summary", lines=8),
],
title="🎤 AI Meeting Notes",
description="Upload audio to get instant transcripts and summaries.",
)
if __name__ == "__main__":
app.launch()
部署您的转录应用程序
现在,让我们将其部署到 Hugging Face Spaces,以便所有人都可以使用它!
- 创建一个新空间:前往 huggingface.co/new-space
- 选择 Gradio SDK 并将其设置为公开
- 上传您的文件:上传
app.py和所有依赖项 - 添加您的令牌:在空间设置中,将
HF_TOKEN添加为密钥 - 配置硬件:考虑使用 GPU 以加快处理速度
- 启动:您的应用程序将在
https://huggingface.co/spaces/your-username/your-space-name上上线
您的转录应用程序现在已准备好处理会议记录、采访、播客以及任何其他需要转录和摘要的音频内容!
下一步
干得好!您现在已经构建了一个具有智能摘要功能的完整转录应用程序。
以下是一些扩展转录应用程序的方法:
- 多语言支持:添加语言检测并支持多种语言
- 说话人识别:使用来自 Hub 的具有说话人分离功能的模型。
- 自定义提示:允许用户自定义摘要格式和样式
- 实现文本转语音:使用来自 Hub 的模型将您的摘要转换为另一个音频文件!