Transformers 文档
OPT
并获得增强的文档体验
开始使用
OPT
概述
OPT 模型由 Meta AI 在论文 《Open Pre-trained Transformer Language Models》 中提出。OPT 是一系列开源的大型因果语言模型,其性能与 GPT3 相似。
论文摘要如下:
大型语言模型通常需要数十万个计算日进行训练,在零样本和少样本学习方面展现了卓越的能力。鉴于其巨大的计算成本,没有雄厚资本很难复现这些模型。对于少数通过 API 提供的模型,也无法访问完整的模型权重,这使得研究它们变得困难。我们推出了开放预训练变换器(OPT),这是一套仅包含解码器的预训练变换器,参数范围从 1.25 亿到 1750 亿,我们希望与感兴趣的研究人员完全且负责任地共享。我们证明了 OPT-175B 的性能与 GPT-3 相当,而开发所需的碳足迹仅为其七分之一。我们还发布了我们的日志,详细记录了我们面临的基础设施挑战,以及用于实验所有已发布模型的代码。
该模型由 Arthur Zucker、Younes Belkada 和 Patrick Von Platen 贡献。原始代码可以在此处找到。
技巧
- OPT 具有与
BartDecoder相同的架构。 - 与 GPT2 不同,OPT 在每个提示的开头添加了 EOS 标记
</s>。
[!NOTE] 当使用除“eager”之外的所有注意力实现时,
head_mask参数会被忽略。如果你有一个head_mask并且希望它生效,请使用XXXModel.from_pretrained(model_id, attn_implementation="eager")加载模型。
资源
一份官方 Hugging Face 和社区(由 🌎 标志表示)资源的列表,帮助您开始使用 OPT。如果您有兴趣提交资源并希望将其包含在此处,请随时发起一个 Pull Request,我们会进行审核。提交的资源最好能展示一些新的内容,而不是重复现有的资源。
- 一份关于使用 PEFT、bitsandbytes 和 Transformers 微调 OPT 的笔记本。🌎
- 一篇关于使用 OPT 进行解码策略的博客文章。
- 🤗 Hugging Face 课程的因果语言建模章节。
- OPTForCausalLM 支持此因果语言建模示例脚本和笔记本。
- TFOPTForCausalLM 支持此因果语言建模示例脚本和笔记本。
- FlaxOPTForCausalLM 支持此因果语言建模示例脚本。
- OPTForQuestionAnswering 支持此问答示例脚本和笔记本。
- 🤗 Hugging Face课程的问答章节。
⚡️ 推理
- 一篇关于🤗 Accelerate 如何借助 PyTorch 和 OPT 运行超大模型的博客文章。
结合 OPT 与 Flash Attention 2
首先,请确保安装最新版本的 Flash Attention 2,以包含滑动窗口注意力功能。
pip install -U flash-attn --no-build-isolation
请确保您拥有与 Flash-Attention 2 兼容的硬件。更多信息请参阅 flash-attn 仓库的官方文档。同时,请确保以半精度(例如 `torch.float16`)加载您的模型。
要加载并使用 Flash Attention 2 运行模型,请参考以下代码片段
>>> import torch
>>> from transformers import OPTForCausalLM, GPT2Tokenizer
>>> device = "cuda" # the device to load the model onto
>>> model = OPTForCausalLM.from_pretrained("facebook/opt-350m", torch_dtype=torch.float16, attn_implementation="flash_attention_2")
>>> tokenizer = GPT2Tokenizer.from_pretrained("facebook/opt-350m")
>>> prompt = ("A chat between a curious human and the Statue of Liberty.\n\nHuman: What is your name?\nStatue: I am the "
"Statue of Liberty.\nHuman: Where do you live?\nStatue: New York City.\nHuman: How long have you lived "
"there?")
>>> model_inputs = tokenizer([prompt], return_tensors="pt").to(device)
>>> model.to(device)
>>> generated_ids = model.generate(**model_inputs, max_new_tokens=30, do_sample=False)
>>> tokenizer.batch_decode(generated_ids)[0]
'</s>A chat between a curious human and the Statue of Liberty.\n\nHuman: What is your name?\nStatue: I am the Statue of Liberty.\nHuman: Where do you live?\nStatue: New York City.\nHuman: How long have you lived there?\nStatue: I have lived here for about a year.\nHuman: What is your favorite place to eat?\nStatue: I love'预期加速效果
下图是一个预期加速图,比较了使用 `facebook/opt-2.7b` 检查点时,transformers 中的原生实现与 Flash Attention 2 版本的模型在两种不同序列长度下的纯推理时间。
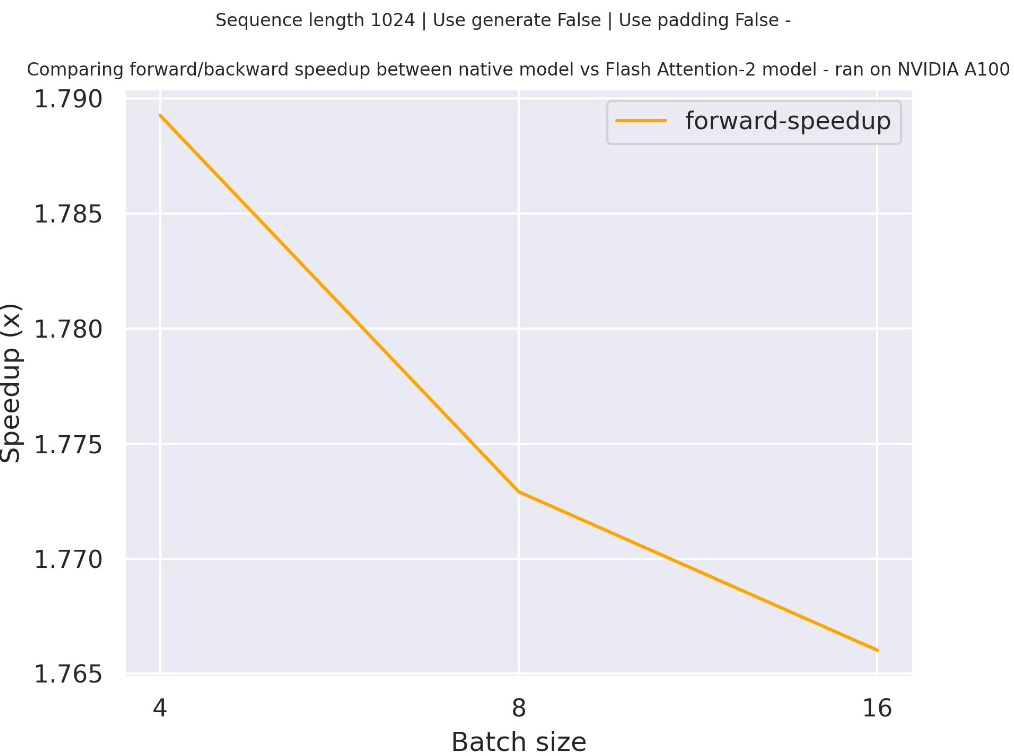
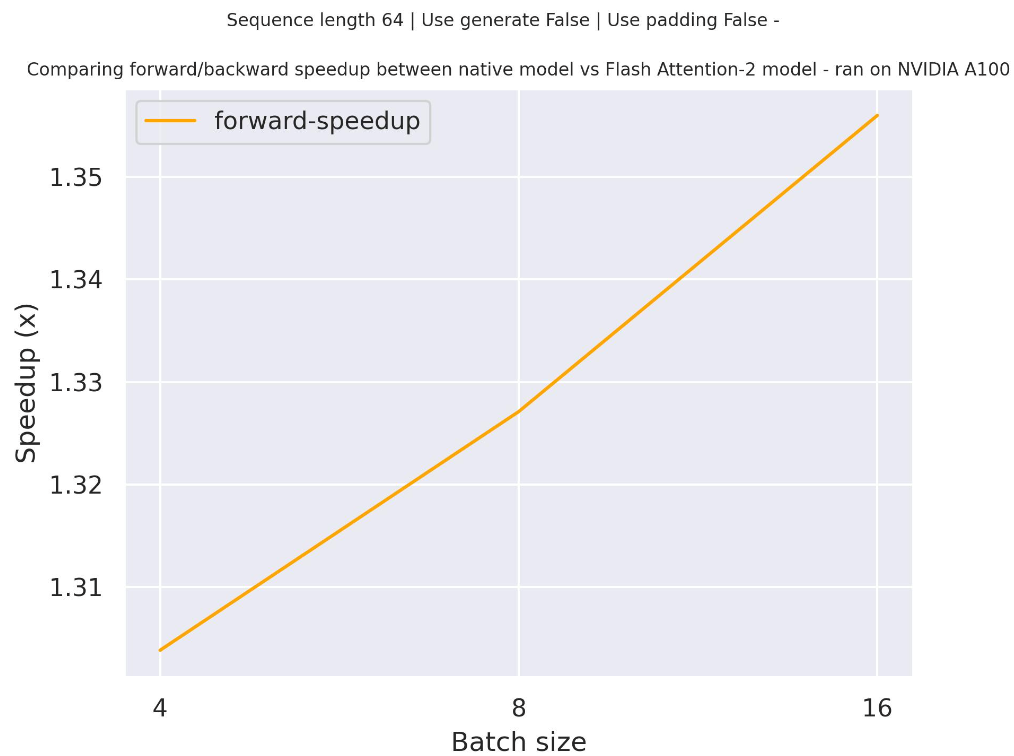
下图是一个预期加速图,比较了使用 `facebook/opt-350m` 检查点时,transformers 中的原生实现与 Flash Attention 2 版本的模型在两种不同序列长度下的纯推理时间。
使用缩放点积注意力 (SDPA)
PyTorch 在 `torch.nn.functional` 中包含一个原生的缩放点积注意力 (SDPA) 算子。该函数包含多种实现,可根据输入和使用的硬件进行应用。更多信息请参阅官方文档或GPU 推理页面。
当实现可用时,SDPA 默认用于 `torch>=2.1.1`,但你也可以在 `from_pretrained()` 中设置 `attn_implementation="sdpa"` 来明确请求使用 SDPA。
from transformers import OPTForCausalLM
model = OPTForCausalLM.from_pretrained("facebook/opt-350m", torch_dtype=torch.float16, attn_implementation="sdpa")
...为了获得最佳加速效果,我们建议以半精度(例如 `torch.float16` 或 `torch.bfloat16`)加载模型。
在本地基准测试(L40S-45GB, PyTorch 2.4.0, OS Debian GNU/Linux 11)中使用 `float16` 和 facebook/opt-350m,我们在训练和推理过程中观察到以下加速效果。
训练
| 批处理大小 | 序列长度 | 每批次时间(Eager - 秒) | 每批次时间(SDPA - 秒) | 加速(%) | Eager 峰值内存(MB) | sdpa 峰值内存 (MB) | 内存节省(%) |
|---|---|---|---|---|---|---|---|
| 1 | 128 | 0.047 | 0.037 | 26.360 | 1474.611 | 1474.32 | 0.019 |
| 1 | 256 | 0.046 | 0.037 | 24.335 | 1498.541 | 1499.49 | -0.063 |
| 1 | 512 | 0.046 | 0.037 | 24.959 | 1973.544 | 1551.35 | 27.215 |
| 1 | 1024 | 0.062 | 0.038 | 65.135 | 4867.113 | 1698.35 | 186.578 |
| 1 | 2048 | 0.230 | 0.039 | 483.933 | 15662.224 | 2715.75 | 476.718 |
| 2 | 128 | 0.045 | 0.037 | 20.455 | 1498.164 | 1499.49 | -0.089 |
| 2 | 256 | 0.046 | 0.037 | 24.027 | 1569.367 | 1551.35 | 1.161 |
| 2 | 512 | 0.045 | 0.037 | 20.965 | 3257.074 | 1698.35 | 91.778 |
| 2 | 1024 | 0.122 | 0.038 | 225.958 | 9054.405 | 2715.75 | 233.403 |
| 2 | 2048 | 0.464 | 0.067 | 593.646 | 30572.058 | 4750.55 | 543.548 |
| 4 | 128 | 0.045 | 0.037 | 21.918 | 1549.448 | 1551.35 | -0.123 |
| 4 | 256 | 0.044 | 0.038 | 18.084 | 2451.768 | 1698.35 | 44.361 |
| 4 | 512 | 0.069 | 0.037 | 84.421 | 5833.180 | 2715.75 | 114.791 |
| 4 | 1024 | 0.262 | 0.062 | 319.475 | 17427.842 | 4750.55 | 266.860 |
| 4 | 2048 | 内存不足 | 0.062 | Eager 内存不足 | 内存不足 | 4750.55 | Eager 内存不足 |
| 8 | 128 | 0.044 | 0.037 | 18.436 | 2049.115 | 1697.78 | 20.694 |
| 8 | 256 | 0.048 | 0.036 | 32.887 | 4222.567 | 2715.75 | 55.484 |
| 8 | 512 | 0.153 | 0.06 | 154.862 | 10985.391 | 4750.55 | 131.245 |
| 8 | 1024 | 0.526 | 0.122 | 330.697 | 34175.763 | 8821.18 | 287.428 |
| 8 | 2048 | 内存不足 | 0.122 | Eager 内存不足 | 内存不足 | 8821.18 | Eager 内存不足 |
推理
| 批处理大小 | 序列长度 | Eager 每词元延迟 (ms) | SDPA 每词元延迟 (ms) | 加速(%) | Eager 内存 (MB) | BT 内存 (MB) | 内存节省 (%) |
|---|---|---|---|---|---|---|---|
| 1 | 128 | 11.634 | 8.647 | 34.546 | 717.676 | 717.674 | 0 |
| 1 | 256 | 11.593 | 8.86 | 30.851 | 742.852 | 742.845 | 0.001 |
| 1 | 512 | 11.515 | 8.816 | 30.614 | 798.232 | 799.593 | -0.17 |
| 1 | 1024 | 11.556 | 8.915 | 29.628 | 917.265 | 895.538 | 2.426 |
| 2 | 128 | 12.724 | 11.002 | 15.659 | 762.434 | 762.431 | 0 |
| 2 | 256 | 12.704 | 11.063 | 14.83 | 816.809 | 816.733 | 0.009 |
| 2 | 512 | 12.757 | 10.947 | 16.535 | 917.383 | 918.339 | -0.104 |
| 2 | 1024 | 13.018 | 11.018 | 18.147 | 1162.65 | 1114.81 | 4.291 |
| 4 | 128 | 12.739 | 10.959 | 16.243 | 856.335 | 856.483 | -0.017 |
| 4 | 256 | 12.718 | 10.837 | 17.355 | 957.298 | 957.674 | -0.039 |
| 4 | 512 | 12.813 | 10.822 | 18.393 | 1158.44 | 1158.45 | -0.001 |
| 4 | 1024 | 13.416 | 11.06 | 21.301 | 1653.42 | 1557.19 | 6.18 |
| 8 | 128 | 12.763 | 10.891 | 17.193 | 1036.13 | 1036.51 | -0.036 |
| 8 | 256 | 12.89 | 11.104 | 16.085 | 1236.98 | 1236.87 | 0.01 |
| 8 | 512 | 13.327 | 10.939 | 21.836 | 1642.29 | 1641.78 | 0.031 |
| 8 | 1024 | 15.181 | 11.175 | 35.848 | 2634.98 | 2443.35 | 7.843 |
OPTConfig
class transformers.OPTConfig
< 来源 >( vocab_size = 50272 hidden_size = 768 num_hidden_layers = 12 ffn_dim = 3072 max_position_embeddings = 2048 do_layer_norm_before = True _remove_final_layer_norm = False word_embed_proj_dim = None dropout = 0.1 attention_dropout = 0.0 num_attention_heads = 12 activation_function = 'relu' layerdrop = 0.0 init_std = 0.02 use_cache = True pad_token_id = 1 bos_token_id = 2 eos_token_id = 2 enable_bias = True layer_norm_elementwise_affine = True **kwargs )
参数
- vocab_size (
int, 可选, 默认为 50272) — OPT 模型的词汇表大小。定义了在调用 OPTModel 时传入的 `inputs_ids` 可以表示的不同标记的数量。 - hidden_size (
int, 可选, 默认为 768) — 层和池化层的维度。 - num_hidden_layers (
int, 可选, 默认为 12) — 解码器层的数量。 - ffn_dim (
int, 可选, 默认为 3072) — 解码器中“中间”(通常称为前馈)层的维度。 - num_attention_heads (
int, 可选, 默认为 12) — Transformer 解码器中每个注意力层的注意力头数量。 - activation_function (
str或function, 可选, 默认为"relu") — 编码器和池化层中的非线性激活函数(函数或字符串)。如果为字符串,支持"gelu"、"relu"、"silu"和"gelu_new"。 - max_position_embeddings (
int, 可选, 默认为 2048) — 该模型可能使用的最大序列长度。通常将其设置为一个较大的值以备不时之需(例如 512、1024 或 2048)。 - do_layer_norm_before (
bool, 可选, 默认为True) — 是否在注意力块之前执行层归一化。 - word_embed_proj_dim (
int, 可选) — `word_embed_proj_dim` 可用于下投影词嵌入,例如 `opt-350m`。默认为 `hidden_size`。 - dropout (
float, 可选, 默认为 0.1) — 嵌入、编码器和池化层中所有全连接层的 dropout 概率。 - attention_dropout (
float, 可选, 默认为 0.0) — 注意力概率的 dropout 比率。 - layerdrop (
float, 可选, 默认为 0.0) — LayerDrop 概率。更多细节请参阅 [LayerDrop 论文](https://huggingface.co/papers/1909.11556)。 - init_std (
float, 可选, 默认为 0.02) — 用于初始化所有权重矩阵的 truncated_normal_initializer 的标准差。 - use_cache (
bool, 可选, 默认为True) — 模型是否应返回最后一个键/值注意力(并非所有模型都使用)。 - enable_bias (
bool, 可选, 默认为True) — 注意力块中的线性层是否应使用偏置项。 - layer_norm_elementwise_affine (
bool, 可选, 默认为True) — 层归一化是否应具有可学习的参数。
这是一个用于存储 OPTModel 配置的配置类。它根据指定的参数实例化一个 OPT 模型,定义模型架构。使用默认值实例化配置将产生与 OPT facebook/opt-350m 架构类似的配置。
配置对象继承自 PretrainedConfig,可用于控制模型输出。请阅读 PretrainedConfig 的文档以获取更多信息。
示例
>>> from transformers import OPTConfig, OPTModel
>>> # Initializing a OPT facebook/opt-large style configuration
>>> configuration = OPTConfig()
>>> # Initializing a model (with random weights) from the facebook/opt-large style configuration
>>> model = OPTModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configOPTModel
class transformers.OPTModel
< source >( config: OPTConfig )
参数
- config (OPTConfig) — 包含模型所有参数的模型配置类。使用配置文件进行初始化不会加载与模型相关的权重,只会加载配置。请查看 from_pretrained() 方法来加载模型权重。
无任何特定头部的原始 Opt 模型,输出原始的隐藏状态。
该模型继承自 PreTrainedModel。请查看超类文档,了解库为所有模型实现的通用方法(例如下载或保存、调整输入嵌入大小、修剪头部等)。
该模型也是 PyTorch torch.nn.Module 的子类。可以像常规 PyTorch 模块一样使用它,并参考 PyTorch 文档了解所有与通用用法和行为相关的事项。
forward
< source >( input_ids: typing.Optional[torch.LongTensor] = None attention_mask: typing.Optional[torch.Tensor] = None head_mask: typing.Optional[torch.Tensor] = None past_key_values: typing.Union[transformers.cache_utils.Cache, list[torch.FloatTensor], NoneType] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None use_cache: typing.Optional[bool] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None position_ids: typing.Optional[torch.LongTensor] = None cache_position: typing.Optional[torch.Tensor] = None **kwargs: typing_extensions.Unpack[transformers.modeling_flash_attention_utils.FlashAttentionKwargs] ) → transformers.modeling_outputs.BaseModelOutputWithPast 或 tuple(torch.FloatTensor)
参数
- input_ids (
torch.LongTensor,形状为(batch_size, sequence_length),可选) — 词汇表中输入序列标记的索引。默认情况下,填充将被忽略。可以使用 AutoTokenizer 获取索引。有关详细信息,请参阅 PreTrainedTokenizer.encode() 和 PreTrainedTokenizer.call()。
- attention_mask (
torch.Tensor,形状为(batch_size, sequence_length),可选) — 用于避免对填充标记索引执行注意力机制的掩码。掩码值选自[0, 1]:- 1 表示标记未被掩码,
- 0 表示标记已被掩码。
- head_mask (
torch.Tensor,形状为(num_heads,)或(num_layers, num_heads),可选) — 用于使自注意力模块的选定头部无效的掩码。掩码值选自[0, 1]:- 1 表示头部未被掩码,
- 0 表示头部已被掩码。
- past_key_values (
Union[~cache_utils.Cache, list[torch.FloatTensor], NoneType]) — 预先计算的隐藏状态(自注意力块和交叉注意力块中的键和值),可用于加速序列解码。这通常包括模型在先前解码阶段返回的past_key_values,当use_cache=True或config.use_cache=True时。允许两种格式:
- 一个 Cache 实例,请参阅我们的 kv 缓存指南;
- 长度为
config.n_layers的tuple(torch.FloatTensor)元组,每个元组包含 2 个形状为(batch_size, num_heads, sequence_length, embed_size_per_head)的张量。这也称为旧版缓存格式。
模型将输出与输入相同的缓存格式。如果未传递
past_key_values,将返回旧版缓存格式。如果使用
past_key_values,用户可以选择只输入最后一个input_ids(那些没有为其提供过去键值状态的 ID),形状为(batch_size, 1),而不是所有形状为(batch_size, sequence_length)的input_ids。 - inputs_embeds (
torch.FloatTensor,形状为(batch_size, sequence_length, hidden_size),可选) — 可选地,你可以不传递input_ids,而是直接传递嵌入表示。如果你想比模型内部的嵌入查找矩阵更好地控制如何将input_ids索引转换为相关向量,这会很有用。 - use_cache (
bool,可选) — 如果设置为True,则返回past_key_values键值状态,可用于加速解码(请参阅past_key_values)。 - output_attentions (
bool,可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量下的attentions。 - output_hidden_states (
bool,可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的hidden_states。 - return_dict (
bool,可选) — 是否返回一个 ModelOutput 而不是一个普通的元组。 - position_ids (
torch.LongTensor,形状为(batch_size, sequence_length),可选) — 每个输入序列标记在位置嵌入中的位置索引。选自[0, config.n_positions - 1]范围。 - cache_position (
torch.Tensor,形状为(sequence_length),可选) — 描述输入序列标记在序列中位置的索引。与position_ids相反,此张量不受填充影响。它用于在正确的位置更新缓存并推断完整的序列长度。
返回
transformers.modeling_outputs.BaseModelOutputWithPast 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.BaseModelOutputWithPast 或一个 `torch.FloatTensor` 元组(如果传递了 `return_dict=False` 或 `config.return_dict=False`),根据配置(OPTConfig)和输入包含各种元素。
-
last_hidden_state (
torch.FloatTensor, 形状为(batch_size, sequence_length, hidden_size)) — 模型最后一层输出的隐藏状态序列。如果使用了
past_key_values,则只输出形状为(batch_size, 1, hidden_size)的序列的最后一个隐藏状态。 -
past_key_values (
Cache,可选,当传递use_cache=True或config.use_cache=True时返回) — 这是一个 Cache 实例。更多详情,请参阅我们的 kv 缓存指南。包含预计算的隐藏状态(自注意力块中的键和值,如果 `config.is_encoder_decoder=True`,则还包括交叉注意力块中的键和值),可用于(参见 `past_key_values` 输入)加速序列解码。
-
hidden_states (
tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或config.output_hidden_states=True时返回) —torch.FloatTensor元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每层输出),形状为(batch_size, sequence_length, hidden_size)。模型在每个层输出的隐藏状态以及可选的初始嵌入输出。
-
attentions (
tuple(torch.FloatTensor),可选,当传递output_attentions=True或config.output_attentions=True时返回) —torch.FloatTensor元组(每层一个),形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
OPTModel 的 forward 方法,覆盖了 `__call__` 特殊方法。
虽然前向传播的流程需要在此函数内定义,但之后应调用 `Module` 实例而不是此函数,因为前者会处理运行前处理和后处理步骤,而后者会静默地忽略它们。
OPTForCausalLM
forward
< source >( input_ids: typing.Optional[torch.LongTensor] = None attention_mask: typing.Optional[torch.Tensor] = None head_mask: typing.Optional[torch.Tensor] = None past_key_values: typing.Union[transformers.cache_utils.Cache, list[torch.FloatTensor], NoneType] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None labels: typing.Optional[torch.LongTensor] = None use_cache: typing.Optional[bool] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None position_ids: typing.Optional[torch.LongTensor] = None cache_position: typing.Optional[torch.Tensor] = None **kwargs: typing_extensions.Unpack[transformers.models.opt.modeling_opt.KwargsForCausalLM] ) → transformers.modeling_outputs.CausalLMOutputWithPast 或 tuple(torch.FloatTensor)
参数
- input_ids (
torch.LongTensor,形状为(batch_size, sequence_length),可选) — 词汇表中输入序列标记的索引。默认情况下,填充将被忽略。可以使用 AutoTokenizer 获取索引。有关详细信息,请参阅 PreTrainedTokenizer.encode() 和 PreTrainedTokenizer.call()。
- attention_mask (
torch.Tensor,形状为(batch_size, sequence_length),可选) — 用于避免对填充标记索引执行注意力机制的掩码。掩码值选自[0, 1]:- 1 表示标记未被掩码,
- 0 表示标记已被掩码。
- head_mask (
torch.Tensor,形状为(num_heads,)或(num_layers, num_heads),可选) — 用于使自注意力模块的选定头部无效的掩码。掩码值选自[0, 1]:- 1 表示头部未被掩码,
- 0 表示头部已被掩码。
- past_key_values (
Union[~cache_utils.Cache, list[torch.FloatTensor], NoneType]) — 预先计算的隐藏状态(自注意力块和交叉注意力块中的键和值),可用于加速序列解码。这通常包括模型在先前解码阶段返回的past_key_values,当use_cache=True或config.use_cache=True时。允许两种格式:
- 一个 Cache 实例,请参阅我们的 kv 缓存指南;
- 长度为
config.n_layers的tuple(torch.FloatTensor)元组,每个元组包含 2 个形状为(batch_size, num_heads, sequence_length, embed_size_per_head)的张量。这也称为旧版缓存格式。
模型将输出与输入相同的缓存格式。如果未传递
past_key_values,将返回旧版缓存格式。如果使用
past_key_values,用户可以选择只输入最后一个input_ids(那些没有为其提供过去键值状态的 ID),形状为(batch_size, 1),而不是所有形状为(batch_size, sequence_length)的input_ids。 - inputs_embeds (
torch.FloatTensor,形状为(batch_size, sequence_length, hidden_size),可选) — 可选地,你可以不传递input_ids,而是直接传递嵌入表示。如果你想比模型内部的嵌入查找矩阵更好地控制如何将input_ids索引转换为相关向量,这会很有用。 - labels (
torch.LongTensor,形状为(batch_size, sequence_length),可选) — 用于计算掩码语言建模损失的标签。索引应在[0, ..., config.vocab_size]或 -100 之间(请参阅input_ids文档字符串)。索引设置为-100的标记将被忽略(掩码),损失仅对标签在[0, ..., config.vocab_size]之间的标记计算。 - use_cache (
bool,可选) — 如果设置为True,则返回past_key_values键值状态,可用于加速解码(请参阅past_key_values)。 - output_attentions (
bool,可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量下的attentions。 - output_hidden_states (
bool,可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的hidden_states。 - return_dict (
bool,可选) — 是否返回一个 ModelOutput 而不是一个普通的元组。 - position_ids (
torch.LongTensor,形状为(batch_size, sequence_length),可选) — 每个输入序列标记在位置嵌入中的位置索引。选自[0, config.n_positions - 1]范围。 - cache_position (
torch.Tensor,形状为(sequence_length),可选) — 描述输入序列标记在序列中位置的索引。与position_ids相反,此张量不受填充影响。它用于在正确的位置更新缓存并推断完整的序列长度。
返回
transformers.modeling_outputs.CausalLMOutputWithPast 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.CausalLMOutputWithPast 或一个 `torch.FloatTensor` 元组(如果传递了 `return_dict=False` 或 `config.return_dict=False`),根据配置(OPTConfig)和输入包含各种元素。
-
loss (
torch.FloatTensor形状为(1,),可选,当提供labels时返回) — 语言建模损失(用于下一个 token 预测)。 -
logits (形状为
(batch_size, sequence_length, config.vocab_size)的torch.FloatTensor) — 语言建模头部的预测分数(SoftMax 之前的每个词汇标记的分数)。 -
past_key_values (
Cache,可选,当传递use_cache=True或config.use_cache=True时返回) — 这是一个 Cache 实例。更多详情,请参阅我们的 kv 缓存指南。包含预计算的隐藏状态(自注意力块中的键和值),可用于(参见
past_key_values输入)加速顺序解码。 -
hidden_states (
tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或config.output_hidden_states=True时返回) —torch.FloatTensor元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每层输出),形状为(batch_size, sequence_length, hidden_size)。模型在每个层输出的隐藏状态以及可选的初始嵌入输出。
-
attentions (
tuple(torch.FloatTensor),可选,当传递output_attentions=True或config.output_attentions=True时返回) —torch.FloatTensor元组(每层一个),形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
OPTForCausalLM 的 forward 方法,覆盖了 `__call__` 特殊方法。
虽然前向传播的流程需要在此函数内定义,但之后应调用 `Module` 实例而不是此函数,因为前者会处理运行前处理和后处理步骤,而后者会静默地忽略它们。
示例
>>> from transformers import AutoTokenizer, OPTForCausalLM
>>> model = OPTForCausalLM.from_pretrained("facebook/opt-350m")
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
>>> prompt = "Hey, are you conscious? Can you talk to me?"
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> # Generate
>>> generate_ids = model.generate(inputs.input_ids, max_length=30)
>>> tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
"Hey, are you conscious? Can you talk to me?\nI'm not conscious. I'm just a little bit of a weirdo."OPTForSequenceClassification
class transformers.OPTForSequenceClassification
< source >( config: OPTConfig )
参数
- config (OPTConfig) — 包含模型所有参数的模型配置类。使用配置文件进行初始化不会加载与模型相关的权重,只会加载配置。请查看 from_pretrained() 方法来加载模型权重。
在 OPT 模型转换器之上带有一个序列分类头部(线性层)。
OPTForSequenceClassification 使用最后一个标记进行分类,与其他因果模型(如 GPT-2)一样。
由于它对最后一个标记进行分类,因此需要知道最后一个标记的位置。如果配置中定义了 pad_token_id,它会找到每行中不是填充标记的最后一个标记。如果没有定义 pad_token_id,它会简单地取批次中每行的最后一个值。由于当传递 inputs_embeds 而不是 input_ids 时它无法猜测填充标记,因此它会做同样的事情(取批次中每行的最后一个值)。
该模型继承自 PreTrainedModel。请查看超类文档,了解库为所有模型实现的通用方法(例如下载或保存、调整输入嵌入大小、修剪头部等)。
该模型也是 PyTorch torch.nn.Module 的子类。可以像常规 PyTorch 模块一样使用它,并参考 PyTorch 文档了解所有与通用用法和行为相关的事项。
forward
< source >( input_ids: typing.Optional[torch.LongTensor] = None attention_mask: typing.Optional[torch.FloatTensor] = None head_mask: typing.Optional[torch.FloatTensor] = None past_key_values: typing.Union[transformers.cache_utils.Cache, list[torch.FloatTensor], NoneType] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None labels: typing.Optional[torch.LongTensor] = None use_cache: typing.Optional[bool] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None position_ids: typing.Optional[torch.LongTensor] = None ) → transformers.modeling_outputs.SequenceClassifierOutputWithPast 或 tuple(torch.FloatTensor)
参数
- input_ids (
torch.LongTensor,形状为(batch_size, sequence_length),可选) — 词汇表中输入序列标记的索引。默认情况下,填充将被忽略。可以使用 AutoTokenizer 获取索引。有关详细信息,请参阅 PreTrainedTokenizer.encode() 和 PreTrainedTokenizer.call()。
- attention_mask (
torch.FloatTensor,形状为(batch_size, sequence_length),可选) — 用于避免对填充标记索引执行注意力机制的掩码。掩码值选自[0, 1]:- 1 表示标记未被掩码,
- 0 表示标记已被掩码。
- head_mask (
torch.FloatTensor,形状为(num_heads,)或(num_layers, num_heads),可选) — 用于使自注意力模块的选定头部无效的掩码。掩码值选自[0, 1]:- 1 表示头部未被掩码,
- 0 表示头部已被掩码。
- past_key_values (
Union[~cache_utils.Cache, list[torch.FloatTensor], NoneType]) — 预先计算的隐藏状态(自注意力块和交叉注意力块中的键和值),可用于加速序列解码。这通常包括模型在先前解码阶段返回的past_key_values,当use_cache=True或config.use_cache=True时。允许两种格式:
- 一个 Cache 实例,请参阅我们的 kv 缓存指南;
- 长度为
config.n_layers的tuple(torch.FloatTensor)元组,每个元组包含 2 个形状为(batch_size, num_heads, sequence_length, embed_size_per_head)的张量。这也称为旧版缓存格式。
模型将输出与输入相同的缓存格式。如果未传递
past_key_values,将返回旧版缓存格式。如果使用
past_key_values,用户可以选择只输入最后一个input_ids(那些没有为其提供过去键值状态的 ID),形状为(batch_size, 1),而不是所有形状为(batch_size, sequence_length)的input_ids。 - inputs_embeds (
torch.FloatTensor,形状为(batch_size, sequence_length, hidden_size),可选) — 可选地,你可以选择直接传递嵌入式表示,而不是传递input_ids。如果你想比模型内部的嵌入查找矩阵更好地控制如何将input_ids索引转换为相关联的向量,这会很有用。 - labels (
torch.LongTensor,形状为(batch_size,),可选) — 用于计算序列分类/回归损失的标签。索引应在[0, ..., config.num_labels - 1]范围内。如果config.num_labels == 1,则计算回归损失(均方损失);如果config.num_labels > 1,则计算分类损失(交叉熵损失)。 - use_cache (
bool,可选) — 如果设置为True,将返回past_key_values键值状态,可用于加速解码(参见past_key_values)。 - output_attentions (
bool,可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量下的attentions。 - output_hidden_states (
bool,可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的hidden_states。 - return_dict (
bool,可选) — 是否返回一个 ModelOutput 而不是一个普通的元组。 - position_ids (
torch.LongTensor,形状为(batch_size, sequence_length),可选) — 每个输入序列词元在位置嵌入中的位置索引。在[0, config.n_positions - 1]范围内选择。
返回
transformers.modeling_outputs.SequenceClassifierOutputWithPast 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.SequenceClassifierOutputWithPast 或一个 torch.FloatTensor 元组(如果传递了 return_dict=False 或 config.return_dict=False),根据配置(OPTConfig)和输入包含不同的元素。
-
loss (形状为
(1,)的torch.FloatTensor,可选,当提供labels时返回) — 分类损失(如果 config.num_labels==1,则为回归损失)。 -
logits (形状为
(batch_size, config.num_labels)的torch.FloatTensor) — 分类(如果 config.num_labels==1,则为回归)分数(SoftMax 之前)。 -
past_key_values (
Cache,可选,当传递use_cache=True或config.use_cache=True时返回) — 这是一个 Cache 实例。更多详情,请参阅我们的 kv 缓存指南。包含预计算的隐藏状态(自注意力块中的键和值),可用于(参见
past_key_values输入)加速顺序解码。 -
hidden_states (
tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或config.output_hidden_states=True时返回) —torch.FloatTensor元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每层输出),形状为(batch_size, sequence_length, hidden_size)。模型在每个层输出的隐藏状态以及可选的初始嵌入输出。
-
attentions (
tuple(torch.FloatTensor),可选,当传递output_attentions=True或config.output_attentions=True时返回) —torch.FloatTensor元组(每层一个),形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
OPTForSequenceClassification 的 forward 方法重写了 __call__ 特殊方法。
虽然前向传播的流程需要在此函数内定义,但之后应调用 `Module` 实例而不是此函数,因为前者会处理运行前处理和后处理步骤,而后者会静默地忽略它们。
单标签分类示例
>>> import torch
>>> from transformers import AutoTokenizer, OPTForSequenceClassification
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
>>> model = OPTForSequenceClassification.from_pretrained("facebook/opt-350m")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> predicted_class_id = logits.argmax().item()
>>> model.config.id2label[predicted_class_id]
...
>>> # To train a model on `num_labels` classes, you can pass `num_labels=num_labels` to `.from_pretrained(...)`
>>> num_labels = len(model.config.id2label)
>>> model = OPTForSequenceClassification.from_pretrained("facebook/opt-350m", num_labels=num_labels)
>>> labels = torch.tensor([1])
>>> loss = model(**inputs, labels=labels).loss
>>> round(loss.item(), 2)
...多标签分类示例
>>> import torch
>>> from transformers import AutoTokenizer, OPTForSequenceClassification
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
>>> model = OPTForSequenceClassification.from_pretrained("facebook/opt-350m", problem_type="multi_label_classification")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> predicted_class_ids = torch.arange(0, logits.shape[-1])[torch.sigmoid(logits).squeeze(dim=0) > 0.5]
>>> # To train a model on `num_labels` classes, you can pass `num_labels=num_labels` to `.from_pretrained(...)`
>>> num_labels = len(model.config.id2label)
>>> model = OPTForSequenceClassification.from_pretrained(
... "facebook/opt-350m", num_labels=num_labels, problem_type="multi_label_classification"
... )
>>> labels = torch.sum(
... torch.nn.functional.one_hot(predicted_class_ids[None, :].clone(), num_classes=num_labels), dim=1
... ).to(torch.float)
>>> loss = model(**inputs, labels=labels).lossOPTForQuestionAnswering
class transformers.OPTForQuestionAnswering
< 源码 >( config: OPTConfig )
参数
- config (OPTConfig) — 模型配置类,包含模型的所有参数。使用配置文件初始化不会加载与模型关联的权重,只会加载配置。请查看 from_pretrained() 方法来加载模型权重。
带有片段分类头的 Opt Transformer,用于像 SQuAD 这样的抽取式问答任务(在 hidden-states 输出之上加一个线性层来计算 `span start logits` 和 `span end logits`)。
该模型继承自 PreTrainedModel。请查看超类文档,了解库为所有模型实现的通用方法(例如下载或保存、调整输入嵌入大小、修剪头部等)。
该模型也是 PyTorch torch.nn.Module 的子类。可以像常规 PyTorch 模块一样使用它,并参考 PyTorch 文档了解所有与通用用法和行为相关的事项。
forward
< 源码 >( input_ids: typing.Optional[torch.LongTensor] = None attention_mask: typing.Optional[torch.FloatTensor] = None head_mask: typing.Optional[torch.FloatTensor] = None past_key_values: typing.Union[transformers.cache_utils.Cache, list[torch.FloatTensor], NoneType] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None start_positions: typing.Optional[torch.LongTensor] = None end_positions: typing.Optional[torch.LongTensor] = None use_cache: typing.Optional[bool] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None position_ids: typing.Optional[torch.LongTensor] = None ) → transformers.modeling_outputs.QuestionAnsweringModelOutput 或 tuple(torch.FloatTensor)
参数
- input_ids (
torch.LongTensor,形状为(batch_size, sequence_length),可选) — 词汇表中输入序列词元的索引。默认情况下,填充将被忽略。可以使用 AutoTokenizer 获取索引。有关详细信息,请参阅 PreTrainedTokenizer.encode() 和 PreTrainedTokenizer.call()。
- attention_mask (
torch.FloatTensor,形状为(batch_size, sequence_length),可选) — 用于避免在填充词元索引上执行注意力的掩码。掩码值在[0, 1]中选择:- 1 表示词元未被掩码,
- 0 表示词元被掩码。
- head_mask (
torch.FloatTensor,形状为(num_heads,)或(num_layers, num_heads),可选) — 用于置零自注意力模块中选定头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部未被掩码,
- 0 表示头部被掩码。
- past_key_values (
Union[~cache_utils.Cache, list[torch.FloatTensor], NoneType]) — 预先计算的隐藏状态(自注意力块和交叉注意力块中的键和值),可用于加速顺序解码。这通常包括模型在解码的先前阶段返回的past_key_values,当use_cache=True或config.use_cache=True时。允许两种格式:
- 一个 Cache 实例,请参阅我们的 kv 缓存指南;
- 一个长度为
config.n_layers的tuple(torch.FloatTensor)元组,每个元组包含 2 个形状为(batch_size, num_heads, sequence_length, embed_size_per_head)的张量。这也称为旧版缓存格式。
模型将输出与输入相同的缓存格式。如果没有传递
past_key_values,将返回旧版缓存格式。如果使用
past_key_values,用户可以选择只输入最后一个input_ids(那些没有给出过去键值状态的词元),形状为(batch_size, 1),而不是所有形状为(batch_size, sequence_length)的input_ids。 - inputs_embeds (
torch.FloatTensor,形状为(batch_size, sequence_length, hidden_size),可选) — 可选地,你可以选择直接传递嵌入式表示,而不是传递input_ids。如果你想比模型内部的嵌入查找矩阵更好地控制如何将input_ids索引转换为相关联的向量,这会很有用。 - start_positions (
torch.LongTensor,形状为(batch_size,),可选) — 标记片段开始位置(索引)的标签,用于计算词元分类损失。位置被限制在序列长度(sequence_length)内。超出序列的位置不计入损失计算。 - end_positions (
torch.LongTensor,形状为(batch_size,),可选) — 标记片段结束位置(索引)的标签,用于计算词元分类损失。位置被限制在序列长度(sequence_length)内。超出序列的位置不计入损失计算。 - use_cache (
bool,可选) — 如果设置为True,将返回past_key_values键值状态,可用于加速解码(参见past_key_values)。 - output_attentions (
bool,可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量下的attentions。 - output_hidden_states (
bool,可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的hidden_states。 - return_dict (
bool,可选) — 是否返回一个 ModelOutput 而不是一个普通的元组。 - position_ids (
torch.LongTensor,形状为(batch_size, sequence_length),可选) — 每个输入序列词元在位置嵌入中的位置索引。在[0, config.n_positions - 1]范围内选择。
返回
transformers.modeling_outputs.QuestionAnsweringModelOutput 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.QuestionAnsweringModelOutput 或一个 torch.FloatTensor 元组(如果传递了 return_dict=False 或 config.return_dict=False),根据配置(OPTConfig)和输入包含不同的元素。
-
loss (
torch.FloatTensorof shape(1,), 可选, 当提供labels时返回) — 总范围提取损失是起始位置和结束位置的交叉熵之和。 -
start_logits (
torch.FloatTensorof shape(batch_size, sequence_length)) — 范围起始分数(SoftMax 之前)。 -
end_logits (
torch.FloatTensorof shape(batch_size, sequence_length)) — 范围结束分数(SoftMax 之前)。 -
hidden_states (
tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或config.output_hidden_states=True时返回) —torch.FloatTensor元组(一个用于嵌入层的输出,如果模型有嵌入层,+ 一个用于每层输出),形状为(batch_size, sequence_length, hidden_size)。模型在每个层输出的隐藏状态以及可选的初始嵌入输出。
-
attentions (
tuple(torch.FloatTensor),可选,当传递output_attentions=True或config.output_attentions=True时返回) —torch.FloatTensor元组(每层一个),形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
OPTForQuestionAnswering 的 forward 方法重写了 __call__ 特殊方法。
虽然前向传播的流程需要在此函数内定义,但之后应调用 `Module` 实例而不是此函数,因为前者会处理运行前处理和后处理步骤,而后者会静默地忽略它们。
示例
>>> from transformers import AutoTokenizer, OPTForQuestionAnswering
>>> import torch
>>> torch.manual_seed(4)
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
>>> # note: we are loading a OPTForQuestionAnswering from the hub here,
>>> # so the head will be randomly initialized, hence the predictions will be random
>>> model = OPTForQuestionAnswering.from_pretrained("facebook/opt-350m")
>>> question, text = "Who was Jim Henson?", "Jim Henson was a nice puppet"
>>> inputs = tokenizer(question, text, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> answer_start_index = outputs.start_logits.argmax()
>>> answer_end_index = outputs.end_logits.argmax()
>>> answer_offset = len(tokenizer(question)[0])
>>> predict_answer_tokens = inputs.input_ids[
... 0, answer_offset + answer_start_index : answer_offset + answer_end_index + 1
... ]
>>> predicted = tokenizer.decode(predict_answer_tokens)
>>> predicted
' a nice puppet'TFOPTModel
class transformers.TFOPTModel
< 源码 >( config: OPTConfig **kwargs )
参数
- config (OPTConfig) — 模型配置类,包含模型的所有参数。使用配置文件初始化不会加载与模型关联的权重,只会加载配置。请查看 from_pretrained() 方法来加载模型权重。
基础的 TF OPT 模型,输出原始的隐藏状态,没有任何特定的头部。此模型继承自 TFPreTrainedModel。请查阅超类文档以了解库为所有模型实现的通用方法(如下载或保存、调整输入嵌入大小、修剪头部等)。
该模型也是 keras.Model 的子类。可以像常规的 TF 2.0 Keras 模型一样使用它,并参考 TF 2.0 文档了解所有与通用用法和行为相关的事项。
transformers 中的 TensorFlow 模型和层接受两种输入格式
- 所有输入作为关键字参数(如 PyTorch 模型),或
- 所有输入作为第一个位置参数中的列表、元组或字典。
支持第二种格式的原因是,Keras 方法在向模型和层传递输入时更喜欢这种格式。由于这种支持,当使用像 `model.fit()` 这样的方法时,一切都应该“正常工作”——只需以 `model.fit()` 支持的任何格式传递您的输入和标签!但是,如果您想在 Keras 方法(如 `fit()` 和 `predict()`)之外使用第二种格式,例如在使用 Keras `Functional` API 创建自己的层或模型时,您可以使用以下三种可能性来将所有输入张量收集到第一个位置参数中:
- 只有一个
input_ids的单个张量,没有其他:model(input_ids) - 长度可变的列表,包含一个或多个输入张量,按文档字符串中给出的顺序:
model([input_ids, attention_mask])或model([input_ids, attention_mask, token_type_ids]) - 一个字典,其中包含一个或多个与文档字符串中给出的输入名称关联的输入张量:
model({"input_ids": input_ids, "token_type_ids": token_type_ids})
请注意,当使用子类化创建模型和层时,您无需担心这些问题,因为您可以像调用任何其他 Python 函数一样传递输入!
调用
< 源码 >( input_ids: TFModelInputType | None = None attention_mask: np.ndarray | tf.Tensor | None = None head_mask: np.ndarray | tf.Tensor | None = None past_key_values: Optional[tuple[tuple[Union[np.ndarray, tf.Tensor]]]] = None inputs_embeds: np.ndarray | tf.Tensor | None = None use_cache: Optional[bool] = None output_attentions: Optional[bool] = None output_hidden_states: Optional[bool] = None return_dict: Optional[bool] = None training: Optional[bool] = False **kwargs ) → transformers.modeling_tf_outputs.TFBaseModelOutputWithPast 或 tuple(tf.Tensor)
参数
- input_ids (
tf.Tensor,形状为({0})) — 词汇表中输入序列词元的索引。可以使用 AutoTokenizer 获取索引。有关详细信息,请参阅 PreTrainedTokenizer.encode() 和 PreTrainedTokenizer.call()。
- attention_mask (
tf.Tensor,形状为({0}),可选) — 用于避免在填充词元索引上执行注意力的掩码。掩码值在[0, 1]中选择:- 1 表示词元未被掩码,
- 0 表示词元被掩码。
- head_mask (
tf.Tensor,形状为(encoder_layers, encoder_attention_heads),可选) — 用于置零编码器中注意力模块选定头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部未被掩码,
- 0 表示头部被掩码。
- past_key_values (长度为
config.n_layers的tuple[tuple[tf.Tensor]]) — 包含预先计算的注意力块的键和值隐藏状态。可用于加速解码。如果使用past_key_values,用户可以选择只输入最后一个decoder_input_ids(那些没有给出过去键值状态的词元),形状为(batch_size, 1),而不是所有形状为(batch_size, sequence_length)的decoder_input_ids。 - use_cache (
bool,可选,默认为True) — 如果设置为True,将返回past_key_values键值状态,可用于加速解码(参见past_key_values)。在训练期间设置为False,在生成期间设置为True。 - output_attentions (
bool,可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量下的attentions。此参数只能在即时执行模式下使用,在图模式下将使用配置中的值。 - output_hidden_states (
bool,可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的hidden_states。此参数只能在即时执行模式下使用,在图模式下将使用配置中的值。 - return_dict (
bool,可选) — 是否返回一个 ModelOutput 而不是一个普通的元组。此参数可以在即时执行模式下使用,在图模式下该值将始终设置为 True。 - training (
bool,可选,默认为False) — 是否以训练模式使用模型(某些模块如 dropout 模块在训练和评估之间有不同的行为)。
返回
transformers.modeling_tf_outputs.TFBaseModelOutputWithPast 或 tuple(tf.Tensor)
一个 transformers.modeling_tf_outputs.TFBaseModelOutputWithPast 或一个 tf.Tensor 元组(如果传递了 return_dict=False 或 config.return_dict=False),根据配置(OPTConfig)和输入包含不同的元素。
-
last_hidden_state (
tf.Tensorof shape(batch_size, sequence_length, hidden_size)) — 模型最后一层输出的隐藏状态序列。如果使用了
past_key_values,则只输出形状为(batch_size, 1, hidden_size)的序列的最后一个隐藏状态。 -
past_key_values (
list[tf.Tensor],可选,在传递use_cache=True或config.use_cache=True时返回) — 长度为config.n_layers的tf.Tensor列表,每个张量的形状为(2, batch_size, num_heads, sequence_length, embed_size_per_head))。包含预先计算的隐藏状态(注意力块中的键和值),可用于(参见
past_key_values输入)加速顺序解码。 -
hidden_states (
tuple(tf.Tensor),可选,在传递output_hidden_states=True或config.output_hidden_states=True时返回) —tf.Tensor的元组(一个用于嵌入的输出 + 一个用于每个层的输出),形状为(batch_size, sequence_length, hidden_size)。模型在每个层输出的隐藏状态加上初始嵌入输出。
-
attentions (
tuple(tf.Tensor),可选,在传递output_attentions=True或config.output_attentions=True时返回) —tf.Tensor的元组(每层一个),形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
TFOPTModel 的 forward 方法重写了 __call__ 特殊方法。
虽然前向传播的流程需要在此函数内定义,但之后应调用 `Module` 实例而不是此函数,因为前者会处理运行前处理和后处理步骤,而后者会静默地忽略它们。
示例
>>> from transformers import AutoTokenizer, TFOPTModel
>>> import tensorflow as tf
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
>>> model = TFOPTModel.from_pretrained("facebook/opt-350m")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="tf")
>>> outputs = model(inputs)
>>> last_hidden_states = outputs.last_hidden_stateTFOPTForCausalLM
class transformers.TFOPTForCausalLM
< 源码 >( config: OPTConfig **kwargs )
参数
- config (OPTConfig) — 模型配置类,包含模型的所有参数。使用配置文件初始化不会加载与模型关联的权重,只会加载配置。请查看 from_pretrained() 方法来加载模型权重。
带有语言建模头的 OPT 模型 Transformer。
此模型继承自 TFPreTrainedModel。请查阅超类文档以了解库为所有模型实现的通用方法(如下载或保存、调整输入嵌入大小、修剪头部等)。
该模型也是 keras.Model 的子类。可以像常规的 TF 2.0 Keras 模型一样使用它,并参考 TF 2.0 文档了解所有与通用用法和行为相关的事项。
transformers 中的 TensorFlow 模型和层接受两种输入格式
- 所有输入作为关键字参数(如 PyTorch 模型),或
- 所有输入作为第一个位置参数中的列表、元组或字典。
支持第二种格式的原因是,Keras 方法在向模型和层传递输入时更喜欢这种格式。由于这种支持,当使用像 `model.fit()` 这样的方法时,一切都应该“正常工作”——只需以 `model.fit()` 支持的任何格式传递您的输入和标签!但是,如果您想在 Keras 方法(如 `fit()` 和 `predict()`)之外使用第二种格式,例如在使用 Keras `Functional` API 创建自己的层或模型时,您可以使用以下三种可能性来将所有输入张量收集到第一个位置参数中:
- 只有一个
input_ids的单个张量,没有其他:model(input_ids) - 长度可变的列表,包含一个或多个输入张量,按文档字符串中给出的顺序:
model([input_ids, attention_mask])或model([input_ids, attention_mask, token_type_ids]) - 一个字典,其中包含一个或多个与文档字符串中给出的输入名称关联的输入张量:
model({"input_ids": input_ids, "token_type_ids": token_type_ids})
请注意,当使用子类化创建模型和层时,您无需担心这些问题,因为您可以像调用任何其他 Python 函数一样传递输入!
调用
< 源码 >( input_ids: TFModelInputType | None = None past_key_values: Optional[tuple[tuple[Union[np.ndarray, tf.Tensor]]]] = None attention_mask: np.ndarray | tf.Tensor | None = None position_ids: np.ndarray | tf.Tensor | None = None head_mask: np.ndarray | tf.Tensor | None = None inputs_embeds: np.ndarray | tf.Tensor | None = None labels: np.ndarray | tf.Tensor | None = None use_cache: Optional[bool] = None output_attentions: Optional[bool] = None output_hidden_states: Optional[bool] = None return_dict: Optional[bool] = None training: Optional[bool] = False **kwargs ) → transformers.modeling_tf_outputs.TFCausalLMOutputWithPast 或 tuple(tf.Tensor)
参数
- input_ids (
torch.LongTensor,形状为(batch_size, sequence_length)) — 词汇表中输入序列词元的索引。如果你提供了填充,默认情况下它会被忽略。可以使用 AutoTokenizer 获取索引。有关详细信息,请参阅 PreTrainedTokenizer.encode() 和 PreTrainedTokenizer.call()。
- attention_mask (
torch.Tensor,形状为(batch_size, sequence_length),可选) — 用于避免在填充词元索引上执行注意力的掩码。掩码值在[0, 1]中选择:- 1 表示词元未被掩码,
- 0 表示词元被掩码。
- head_mask (
torch.Tensor,形状为(num_hidden_layers, num_attention_heads),可选) — 用于置零注意力模块中选定头部的掩码。掩码值在[0, 1]中选择:- 1 表示头部未被掩码,
- 0 表示头部被掩码。
- past_key_values (
tuple(tuple(torch.FloatTensor)),可选,在传递use_cache=True或config.use_cache=True时返回) — 长度为config.n_layers的tuple(torch.FloatTensor)元组,每个元组包含 2 个形状为(batch_size, num_heads, sequence_length, embed_size_per_head)的张量和 2 个额外的形状为(batch_size, num_heads, encoder_sequence_length, embed_size_per_head)的张量。只有当模型用作序列到序列模型中的解码器时,才需要这两个额外的张量。包含预先计算的隐藏状态(自注意力块和交叉注意力块中的键和值),可用于(参见
past_key_values输入)加速顺序解码。如果使用
past_key_values,用户可以选择只输入最后一个input_ids(那些没有给出过去键值状态的词元),形状为(batch_size, 1),而不是所有形状为(batch_size, sequence_length)的decoder_input_ids。 - inputs_embeds (
torch.FloatTensor,形状为(batch_size, sequence_length, hidden_size),可选) — 可选地,你可以选择直接传递嵌入式表示,而不是传递input_ids。如果你想比模型内部的嵌入查找矩阵更好地控制如何将input_ids索引转换为相关联的向量,这会很有用。 - labels (
torch.LongTensor,形状为(batch_size, sequence_length),可选) — 用于计算掩码语言建模损失的标签。索引应在[0, ..., config.vocab_size]或 -100 之间(参见input_ids文档字符串)。索引设置为-100的词元将被忽略(掩码),损失仅针对标签在[0, ..., config.vocab_size]中的词元进行计算。 - use_cache (
bool,可选) — 如果设置为True,将返回past_key_values键值状态,可用于加速解码(参见past_key_values)。 - output_attentions (
bool,可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量下的attentions。 - output_hidden_states (
bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的hidden_states。 - return_dict (
bool, 可选) — 是否返回一个 ModelOutput 而不是一个普通的元组。
返回
transformers.modeling_tf_outputs.TFCausalLMOutputWithPast 或 tuple(tf.Tensor)
transformers.modeling_tf_outputs.TFCausalLMOutputWithPast 或一个 `tf.Tensor` 元组(如果传递了 `return_dict=False` 或 `config.return_dict=False`),包含的各种元素取决于配置 (OPTConfig) 和输入。
-
loss (形状为
(n,)的tf.Tensor,可选,其中n是非掩码标签的数量,当提供了labels时返回) — 语言建模损失(用于下一标记预测)。 -
logits (
tf.Tensorof shape(batch_size, sequence_length, config.vocab_size)) — 语言模型头部的预测分数(SoftMax 之前每个词汇标记的分数)。 -
past_key_values (
list[tf.Tensor],可选,在传递use_cache=True或config.use_cache=True时返回) — 长度为config.n_layers的tf.Tensor列表,每个张量的形状为(2, batch_size, num_heads, sequence_length, embed_size_per_head))。包含预先计算的隐藏状态(注意力块中的键和值),可用于(参见
past_key_values输入)加速顺序解码。 -
hidden_states (
tuple(tf.Tensor),可选,在传递output_hidden_states=True或config.output_hidden_states=True时返回) —tf.Tensor的元组(一个用于嵌入的输出 + 一个用于每个层的输出),形状为(batch_size, sequence_length, hidden_size)。模型在每个层输出的隐藏状态加上初始嵌入输出。
-
attentions (
tuple(tf.Tensor),可选,在传递output_attentions=True或config.output_attentions=True时返回) —tf.Tensor的元组(每层一个),形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
transformers.modeling_tf_outputs.TFCausalLMOutputWithPast 或 tuple(tf.Tensor):一个 transformers.modeling_tf_outputs.TFCausalLMOutputWithPast 或一个 `tf.Tensor` 元组(如果传递了 `return_dict=False` 或 `config.return_dict=False`),包含的各种元素取决于配置 (OPTConfig) 和输入。
-
loss (形状为
(n,)的tf.Tensor,可选,其中n是非掩码标签的数量,当提供了labels时返回) — 语言建模损失(用于下一标记预测)。 -
logits (
tf.Tensorof shape(batch_size, sequence_length, config.vocab_size)) — 语言模型头部的预测分数(SoftMax 之前每个词汇标记的分数)。 -
past_key_values (
list[tf.Tensor],可选,在传递use_cache=True或config.use_cache=True时返回) — 长度为config.n_layers的tf.Tensor列表,每个张量的形状为(2, batch_size, num_heads, sequence_length, embed_size_per_head))。包含预先计算的隐藏状态(注意力块中的键和值),可用于(参见
past_key_values输入)加速顺序解码。 -
hidden_states (
tuple(tf.Tensor),可选,在传递output_hidden_states=True或config.output_hidden_states=True时返回) —tf.Tensor的元组(一个用于嵌入的输出 + 一个用于每个层的输出),形状为(batch_size, sequence_length, hidden_size)。模型在每个层输出的隐藏状态加上初始嵌入输出。
-
attentions (
tuple(tf.Tensor),可选,在传递output_attentions=True或config.output_attentions=True时返回) —tf.Tensor的元组(每层一个),形状为(batch_size, num_heads, sequence_length, sequence_length)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
示例
>>> from transformers import AutoTokenizer, TFOPTForCausalLM
>>> import tensorflow as tf
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
>>> model = TFOPTForCausalLM.from_pretrained("facebook/opt-350m")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="tf")
>>> outputs = model(inputs)
>>> logits = outputs.logitsFlaxOPTModel
class transformers.FlaxOPTModel
< 源代码 >( config: OPTConfig input_shape: tuple = (1, 1) seed: int = 0 dtype: dtype = <class 'jax.numpy.float32'> _do_init: bool = True **kwargs )
__call__
< 源代码 >( input_ids: Array attention_mask: typing.Optional[jax.Array] = None position_ids: typing.Optional[jax.Array] = None params: typing.Optional[dict] = None past_key_values: typing.Optional[dict] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None dropout_rng: <function PRNGKey at 0x7effc7ad3a30> = None deterministic: bool = True ) → transformers.modeling_flax_outputs.FlaxBaseModelOutput 或 tuple(torch.FloatTensor)
返回
transformers.modeling_flax_outputs.FlaxBaseModelOutput 或 tuple(torch.FloatTensor)
一个 transformers.modeling_flax_outputs.FlaxBaseModelOutput 或一个 `torch.FloatTensor` 元组(如果传递了 `return_dict=False` 或 `config.return_dict=False`),包含的各种元素取决于配置 (OPTConfig) 和输入。
-
last_hidden_state (形状为
(batch_size, sequence_length, hidden_size)的jnp.ndarray) — 模型最后一层输出的隐藏状态序列。 -
hidden_states (
tuple(jnp.ndarray), 可选, 当传递 `output_hidden_states=True` 或 `config.output_hidden_states=True` 时返回) — `jnp.ndarray` 的元组(一个用于词嵌入的输出,另一个用于每层的输出),形状为 `(batch_size, sequence_length, hidden_size)`。模型在每个层输出的隐藏状态加上初始嵌入输出。
-
attentions (
tuple(jnp.ndarray), 可选, 当传递 `output_attentions=True` 或 `config.output_attentions=True` 时返回) — `jnp.ndarray` 的元组(每层一个),形状为 `(batch_size, num_heads, sequence_length, sequence_length)`。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
示例
>>> from transformers import AutoTokenizer, FlaxOPTModel
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
>>> model = FlaxOPTModel.from_pretrained("facebook/opt-350m")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="jax")
>>> outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_stateFlaxOPTForCausalLM
class transformers.FlaxOPTForCausalLM
< 源代码 >( config: OPTConfig input_shape: tuple = (1, 1) seed: int = 0 dtype: dtype = <class 'jax.numpy.float32'> _do_init: bool = True **kwargs )
参数
- config (OPTConfig) — 模型配置类,包含模型的所有参数。使用配置文件进行初始化不会加载与模型相关的权重,只会加载配置。请查看 from_pretrained() 方法来加载模型权重。
- dtype (
jax.numpy.dtype, 可选, 默认为 `jax.numpy.float32`) — 计算的数据类型。可以是 `jax.numpy.float32`、`jax.numpy.float16` (在 GPU 上) 和 `jax.numpy.bfloat16` (在 TPU 上) 之一。这可用于在 GPU 或 TPU 上启用混合精度训练或半精度推理。如果指定,所有计算都将使用给定的 `dtype` 执行。
请注意,这仅指定计算的 dtype,不影响模型参数的 dtype。
带有一个语言建模头的 OPT 模型(线性层,其权重与输入嵌入层绑定),例如用于自回归任务。
该模型继承自 FlaxPreTrainedModel。查阅超类文档,了解该库为其所有模型实现的通用方法(例如下载或保存、调整输入嵌入大小、修剪头等)。
该模型也是 Flax Linen flax.nn.Module 的子类。可将其用作常规的 Flax 模块,并参考 Flax 文档了解所有与常规用法和行为相关的事项。
最后,此模型支持固有的 JAX 功能,例如
__call__
< 源代码 >( input_ids: Array attention_mask: typing.Optional[jax.Array] = None position_ids: typing.Optional[jax.Array] = None params: typing.Optional[dict] = None past_key_values: typing.Optional[dict] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None dropout_rng: <function PRNGKey at 0x7effc7ad3a30> = None deterministic: bool = True ) → transformers.modeling_flax_outputs.FlaxBaseModelOutput 或 tuple(torch.FloatTensor)
返回
transformers.modeling_flax_outputs.FlaxBaseModelOutput 或 tuple(torch.FloatTensor)
一个 transformers.modeling_flax_outputs.FlaxBaseModelOutput 或一个 `torch.FloatTensor` 元组(如果传递了 `return_dict=False` 或 `config.return_dict=False`),包含的各种元素取决于配置 (OPTConfig) 和输入。
-
last_hidden_state (形状为
(batch_size, sequence_length, hidden_size)的jnp.ndarray) — 模型最后一层输出的隐藏状态序列。 -
hidden_states (
tuple(jnp.ndarray), 可选, 当传递 `output_hidden_states=True` 或 `config.output_hidden_states=True` 时返回) — `jnp.ndarray` 的元组(一个用于词嵌入的输出,另一个用于每层的输出),形状为 `(batch_size, sequence_length, hidden_size)`。模型在每个层输出的隐藏状态加上初始嵌入输出。
-
attentions (
tuple(jnp.ndarray), 可选, 当传递 `output_attentions=True` 或 `config.output_attentions=True` 时返回) — `jnp.ndarray` 的元组(每层一个),形状为 `(batch_size, num_heads, sequence_length, sequence_length)`。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
示例
>>> from transformers import AutoTokenizer, FlaxOPTForCausalLM
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
>>> model = FlaxOPTForCausalLM.from_pretrained("facebook/opt-350m")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="np")
>>> outputs = model(**inputs)
>>> # retrieve logts for next token
>>> next_token_logits = outputs.logits[:, -1]